

机器学习(六):逻辑回归
机器学习有两大任务:回归与分类。回归任务是我们求解一个函数式,使其能够对某一个输入有正确的输出,例如我们之前文章中介绍的房价预测,便是给定输入(面积),有正确地输出(正确地预测房价)。分类任务是要求机器对于给定的输入,能够正确地将其归类,比如猫狗识别,我们输入一个小动物,机器需要判定其是猫还是狗。两者本质上都是需要机器拟合出一个关系式,对于某一个输入能有正确的输出。不同的是,回归任务的输出可能有无限个,而分类任务的输出有限,且对于某一个任务,其输出个数固定。
回归任务的拟合十分简单,我们只需要将我们每一步的预测结果与真实值进行对比,然后运用梯度下降法,不断减小误差即可。接下来我们将介绍一下,如何将分类任务抽象成数学语言,进而通过编程来实现。
一、logistic分布与sigmoid函数
首先,我们来介绍一下logistic分布。其分布函数如下:
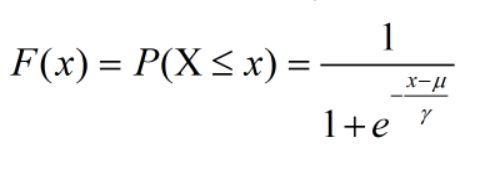
当μ=0,γ=1时,分布函数简化为:
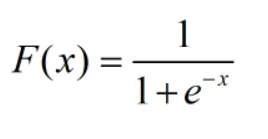
此时的logistic分布在机器学习中也被称为sigmoid函数,其函数图像为:
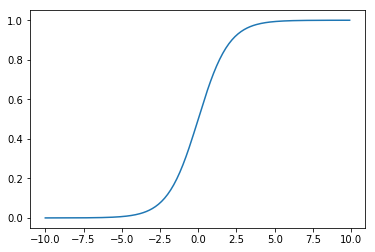
二、逻辑(logistic)回归和二分类任务的实现
根据以上介绍,我们发现,sigmoid函数的输出在0~1之间,具有概率特性。因此,我们可以将sigmoid函数的输出作为判断输入是否为某一类的概率。这就是逻辑回归。我们将逻辑回归模型记为:
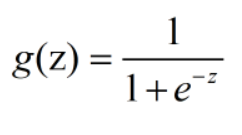
其中z我们可以设为线性回归的模型:
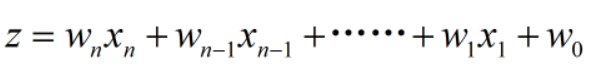
借助于逻辑回归,我们便可以实现简单的二分类任务。下面是实现二分类任务的步骤:
- 人为规定正类和负类,正类记为1,负类记为0
- 设定阈值t,当sigmoid函数的输出大于t时,认为输出为1(正类),否则,认为输出为0(负类)
- 采集数据集,在此数据集上进行训练,选取一组最佳参数w,使得训练集中正类数据的sigmoid函数输出最大,负类的函数输出最小。即模型判别正类数据为正类的概率最大,判别负类数据为正类的概率最小。总的来说,就是寻找最佳参数w,使得最终函数预测出正确结果的概率最大。
- 使用训练好的模型进行预测,当sigmoid函数的输出大于阈值t,则记为正类,否则记为负类
训练过程我们依旧采用梯度下降法。那么问题来了,二分类任务中的损失函数如何设置?如何进行梯度下降才能选取最佳的参数w,使得最终函数能预测出正确结果的概率最大呢?
首先设真实输出为y,y=1对应正类样本,y=0对应负类样本。则单个样本预测正确的概率可以表示为:当样本为正类时,预测正确的概率直接等于模型预测样本为正类的概率;当样本为负类时,预测正确的概率等于模型预测样本为负类的概率,用数学语言描述为:
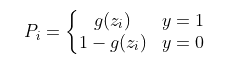
得到了单个样本预测正确的概率,我们便可以得出所有训练集预测正确的概率:
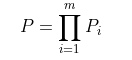
两边取对数,可以将连乘变换为求和,简化运算。
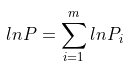
进一步化简,可将分段函数转换为与y有关的表达式:

大家可以自行验证一下化简过程,这里不再赘述。
我们的目的是求出一组参数w,使得P总最大,此时对应损失函数最小,因此我们可以将损失函数J设置为P总的相反数,即对P总取负值。最终的损失函数为:
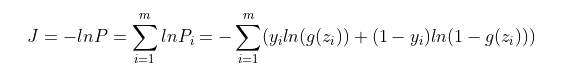
这个损失函数在机器学习中被称为交叉熵损失函数
对交叉熵损失函数求导,得到:
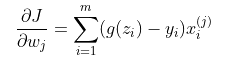
当对上式除以样本数m时,该式子的形式和线性回归梯度的形式一致。
参数的更新:

其中a是学习率,决定每次参数更新的步长。
下面,我们将具体编程实现基于逻辑回归的二分类。
三、编程实现
首先,我们介绍一下这次二分类任务的数据集:
我们使用的数据集是sklearn自带的鸢尾花数据集,该数据集一共记录了鸢尾花的四个特征以及三个属种,我们此次演示二元二分类的情况,因此只取前两种特征和两类鸢尾花数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris=datasets.load_iris()# 导入数据集
x=iris.data
y=iris.target
# 考虑到简单的二元二分类,只取两个类别
x=x[y<2]
y=y[y<2]
# 取前两个特征
x=x[:,:2]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
将数据集划分为训练集和测试集,此处用到sklearn库中的train_test_split函数该函数的输出为划分好的训练集和测试集的特征和标签,输入为待划分数据的特征和标签、测试集的占比以及随机数种子,划分数据集代码:
# 划分数据集,训练集占比为0.8
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=123)- 1
- 2
- 3
- 4
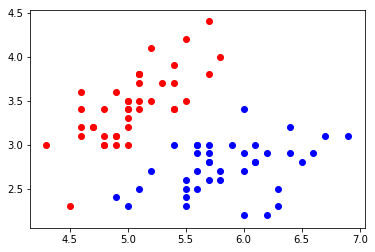
绘制训练集和测试集的分布,训练集:
# 将训练数据集绘制在二维平面
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='red')
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='blue')- 1
- 2
- 3
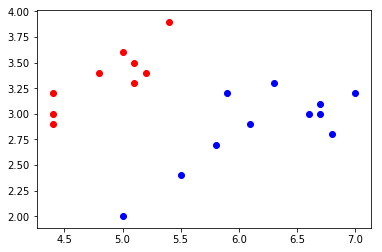
测试集:
# 将测试数据集绘制在二维平面
plt.scatter(x_test[y_test==0,0],x_test[y_test==0,1],color='red')
plt.scatter(x_test[y_test==1,0],x_test[y_test==1,1],color='blue')- 1
- 2
- 3
训练部分代码:
按照上文介绍的部分,编写训练部分代码:
# 初始化参数w1,w2
w1=0
w2=0
x1=x_train[:,0]
x2=x_train[:,1]
# 定义迭代次数和学习率
iter=1000
lr=0.5
# 开始训练
for i in range(1,iter+1):
# 逻辑回归模型
z=w1*x1+w2*x2
g=1/(1+np.exp(-z))
# 损失函数
J=-np.mean(y_train*np.log(g)+(1-y_train)*np.log(1-g))
if i == 1:
cost=J
else:
cost=np.append(cost,J)
# 损失函数求导
grad_J_w1=np.mean((g-y_train)*x1)
grad_J_w2=np.mean((g-y_train)*x2)
# 参数更新
w1=w1-lr*grad_J_w1
w2=w2-lr*grad_J_w2
# 打印参数情况
if i%100 == 0:
print('iter=%d,' % i)
print('cost:%.3f,' % J)
print('w1=%.3f,' % w1)
print('w2=%.3f' % w2)
print('\n')
# 绘制损失函数曲线
plt.plot(cost)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
训练结果:

算法收敛,最终损失函数为0.069
一般情况下,我们都将分类阈值设置为0.5,则分类决策边界为g(z)=0.5,因此决策边界的函数为z=0,即w1x1+w2x2=0,将决策边界绘制出来,结果如下:
训练集:

测试集:
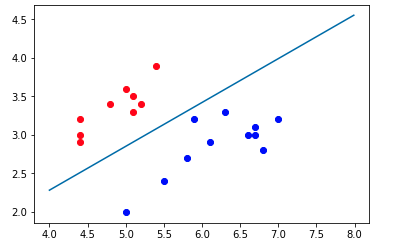
可以看出,训练集和测试集都被决策边界完美分开,决策边界的一边是一类,另一边是另外一类,这就同上文介绍的一样,当用此模型进行分类时,判别式g(z)大于阈值时,分为一类,当g(z)小于阈值时,分为另一类。
四、总结
本文对逻辑回归的理论以及编程实现进行了一个简单的介绍,其中使用的数据集为线性可分的,即可以找到一条直线作为决策边界将两类数据分开,因此理论上来说,分类正确率可以达到100%。但是现实生活中,分类任务绝不会像这样简单,所以我们经常会在此基础上进行改进,例如将sigmoid的输入z变为非线性函数。此外,逻辑回归也会像线性回归出现过拟合的现象,不过解决方法类似,这里不再赘述。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5742次2021-02-20 17:09:58
-
浏览量:5170次2021-07-26 11:25:51
-
浏览量:5044次2021-07-02 14:29:53
-
浏览量:11024次2021-02-21 21:57:48
-
浏览量:3528次2019-09-18 22:22:32
-
浏览量:4347次2021-06-30 11:34:00
-
浏览量:5295次2021-02-21 22:45:39
-
2023-01-13 11:35:13
-
浏览量:1152次2023-07-22 09:54:51
-
浏览量:5766次2021-04-20 15:43:03
-
浏览量:707次2023-09-18 15:02:26
-
浏览量:5150次2021-08-05 09:20:49
-
浏览量:5018次2021-08-05 09:21:07
-
浏览量:834次2023-07-27 11:16:16
-
浏览量:9936次2021-04-20 15:42:26
-
浏览量:664次2023-07-25 09:23:16
-
浏览量:4027次2022-09-22 11:37:57
-
浏览量:3382次2022-06-08 14:16:22
-
浏览量:899次2023-04-23 09:46:58






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
技术凯

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
