

机器学习(五):过拟合现象的产生与解决方法
上篇文章,我们分析了模型复杂度与模型性能的关系,我们发现,模型越复杂,模型在训练集上的误差会越小,但是在测试集上的误差并不一定变小,甚至有可能变大。上述现象我们称为发生了过拟合。下面我们将详细介绍过拟合现象的产生原因以及解决方法。
一、过拟合现象的产生原因
过拟合现象是指一个模型在训练集上表现优异,但在测试集上表现一般,甚至无法正确预测测试集数据的现象。举个生动的例子:我们在玩网络游戏时,常规的步骤是先进行AI(机器人)练习,等AI模式练习的差不多了,才会进行到线上与真人玩家对战。现在拿某一款射击游戏为例,我们从基本的前后左右移动、射击开始练习,从一开始的被AI血虐,一直到熟练进行常规操作,可以轻而易举地猎杀AI敌人。此时,我们便可以到线上与真人玩家pk。或许我们到了线上一样可以“猎杀”真人玩家,或许我们在AI模式下carry全场,却在线上模式依旧被人血虐。我们可以把上述过程中的AI练习看作是机器学习的训练过程,线上模式看作是机器学习对于未知数据(测试集)的预测过程。现在出现一种情况,我们玩的这款游戏的AI机制特别简单,我们在玩到一定程度后发现:AI只有2维视角,也就是说AI看不到它头顶的东西,因此我们只要占领一个制高点,我们就永远不会被AI发现,也就可以carry全场了。于是我们在发现这个机制后,疯狂联系跳跃操作,在AI发现我们之前占领制高点。又过了一段时间后,我们可以做到AI胜率接近100%,我们信心慢慢的进入了线上模式,但是无论我们占领的制高点位置有多好,我们占领的速度有多快,我们都会被敌人发现并且击毙,线上模式体验极差……
上述这个过程很生动地解释了过拟合现象的产生原因。我们来总结一下:一方面,如果训练集比较少,分布比较简单(AI机制简单),我们的网络便不能考虑到所有情况(没有考虑到敌人拥有3D视角),因此很容易发生过拟合现象(能够血虐AI,却被真人玩家血虐)。另一方面,如果我们的模型过于复杂(在AI模式下想的太多,自作聪明,以为自己发现了必胜之道),考虑到了训练数据中的噪声信息等其他无关信息(发现AI只有2维视角这个漏洞),也会发生过拟合现象。综合考虑,过拟合产生的原因就是数据集与模型复杂度不匹配,即数据集的数量无法支撑高复杂度的模型时,便会发生过拟合现象。
二、过拟合现象的解决方案
前面讲到,过拟合现象的产生有两方面的原因:模型过于复杂和数据集过于简单。因此我们可以从两方面入手来解决过拟合的问题:扩展数据集和简化模型。
1、扩展数据集
扩展数据集就是增加数据集的数量,也可以对数据集进行一些变换。总之,最终的目的是让数据集变得复杂。我们上一篇文章中只用了10个数据进行训练,这次,我们将所有的数据均用来训练我们的七次模型,来看一看效果:
首先,导入数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
# 导入数据
datasFile=pd.read_csv('data/data1810/data.txt',names=['size','price'])
datas=np.array(datasFile)
# 取所有数据进行实验,并划分数据集,600个训练数据和270个测试数据
trainSet=datas[0:600,:]
testSet=datas[600:,:]
trainX=trainSet[:,0]
trainY=trainSet[:,1]
testX=testSet[:,0]
testY=testSet[:,1]
# 归一化数据,最大最小值按照训练数据集来取
trainX_min_max=(trainX-np.min(trainX))/(np.max(trainX)-np.min(trainX));
trainY_min_max=(trainY-np.min(trainY))/(np.max(trainY)-np.min(trainY));
testX_min_max=(testX-np.min(testX))/(np.max(testX)-np.min(testX));
testY_min_max=(testY-np.min(testY))/(np.max(testY)-np.min(testY));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
开始训练:
import random
# 初始化回归相关参数值
a=random.random()# 随机初始化一个值
b=random.random()
c=random.random()
d=random.random()
e=random.random()
f=random.random()
g=random.random()
h=random.random()
x=trainX_min_max
y=trainY_min_max
lr=0.1# 学习率
iter=1000 # 训练次数
cost=0
# 开始训练
for i in range(1,iter+1):
predict=a*np.power(x,7)+b*np.power(x,6)+c*np.power(x,5)+d*np.power(x,4)+e*np.power(x,3)+f*np.power(x,2)+g*x+h # 使用七次函数预测
# 计算损失函数
J=np.mean((predict-y)*(predict-y))
cost=np.append(cost,J)
# 计算损失函数的梯度值
J_grad_a=np.mean((predict-y)*np.power(x,7))
J_grad_b=np.mean((predict-y)*np.power(x,6))
J_grad_c=np.mean((predict-y)*np.power(x,5))
J_grad_d=np.mean((predict-y)*np.power(x,4))
J_grad_e=np.mean((predict-y)*np.power(x,3))
J_grad_f=np.mean((predict-y)*np.power(x,2))
J_grad_g=np.mean((predict-y)*x)
J_grad_h=np.mean(predict-y)
# 进行参数迭代
a=a-lr*J_grad_a
b=b-lr*J_grad_b
c=c-lr*J_grad_c
d=d-lr*J_grad_d
e=e-lr*J_grad_e
f=f-lr*J_grad_f
g=g-lr*J_grad_g
h=h-lr*J_grad_h
# 打印参数的值
if i % 100 == 0:
print("iter=%d," % i)
print("cost=%.3f" % J)
print("a=%.3f," % a)
print("b=%.3f," % b)
print("c=%.3f," % c)
print("d=%.3f," % d)
print("e=%.3f," % e)
print("f=%.3f," % f)
print("g=%.3f," % g)
print("h=%.3f," % h)
print("\n")
plt.plot(cost)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
结果如下:
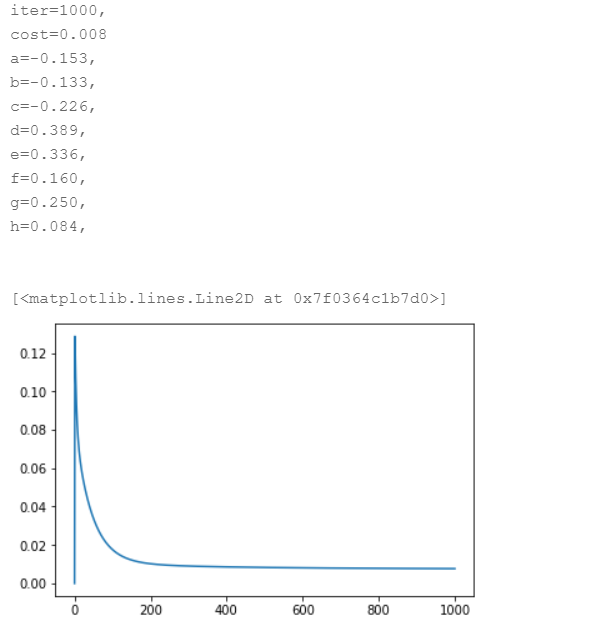
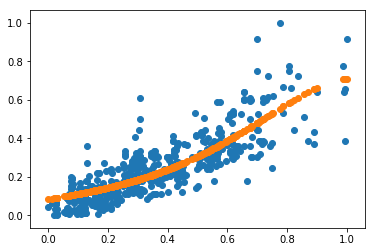
可以看到算法收敛,误差为0.008
测试集效果:
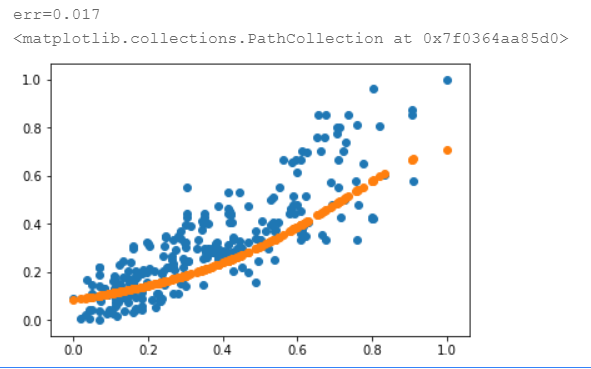
最终误差为0.017
我们可以和之前文章中使用线性模型和二次模型的效果进行对比,如下表:

能够看出来,过拟合现象被充分缓解。其实,扩展数据集的作用是增加模型对数据的稳定性,数据集越复杂,模型就越稳定,能够容忍的模型复杂度就越高。这就是通过扩展数据来客服过拟合问题的原理。
2、正则化处理
第二个解决过拟合问题的方法是简化模型。简化模型可以通过两种途径实现:一种是降低模型的次数,从上篇文章可以看出,线性模型(一次模型)和二次模型能够在测试集上获得不错的性能。另一种就是正则化处理,所谓正则化,就是在损失函数中额外加入与高次参数有关的项,这样在梯度下降法中,算法会考虑对高次参数的惩罚,降低高次参数的影响,这样,既能够缓解过拟合带来的问题,增强模型的泛化能力(推广到未知数据的能力),又能够保留高次项,保证足够的准确度。因此,我们通常使用正则化的处理方法,来解决过拟合问题。
加入正则化的损失函数:
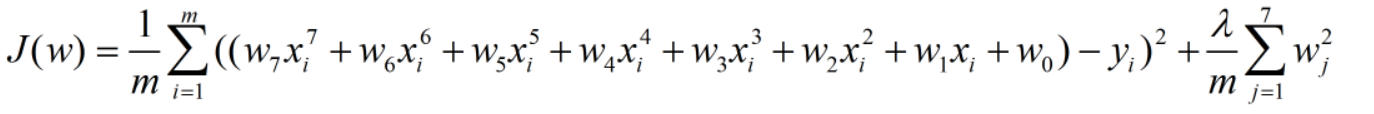
为了方便表达,我们将参数a,b,c等替换为了wi(i=1,2,……,7)。可以看出,我们只是在损失函数后面加入了所有参数(除去常数项)的平均值再乘以一个常数λ,便可实现过拟合现象的抑制。下面我们来简单介绍一下原理。
首先我们来看一下修正后的损失函数对于各项参数的偏导值:

我们发现,在损失函数修正后,它对每个参数的偏导值都将变大,这样,在参数的迭代过程中:
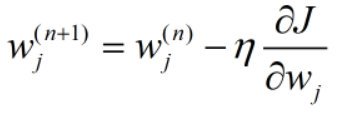
参数每一步迭代都将会减去一个更大的值,而这个值由常数λ来决定,因此称为λ为惩罚系数,顾名思义,λ越大,参数会被“惩罚”得越厉害,最终参数值会越小,拟合出来的函数会越平滑。我们知道,函数的次数越多,函数将越陡峭,通过正则化处理后的函数会变得平滑,这也可以等效为降低了模型的次数,但又同时保留了模型的高次项,保证了模型的性能。在实际训练中,我们要根据数据自主选择最优的λ值,以保证正确率和模型泛化能力的平衡。下面我们进行编程,来观察一下加入正则化后的效果:
首先导入数据,同样,训练集为10个数据,测试集为5个数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
# 导入数据
datasFile=pd.read_csv('data/data1810/data.txt',names=['size','price'])
datas=np.array(datasFile)
# 取前15个数据进行实验,并划分数据集,10个训练数据和5个测试数据
trainSet=datas[0:10,:]
testSet=datas[10:15,:]
trainX=trainSet[:,0]
trainY=trainSet[:,1]
testX=testSet[:,0]
testY=testSet[:,1]
# 归一化数据,最大最小值按照训练数据集来取
trainX_min_max=(trainX-np.min(trainX))/(np.max(trainX)-np.min(trainX));
trainY_min_max=(trainY-np.min(trainY))/(np.max(trainY)-np.min(trainY));
testX_min_max=(testX-np.min(testX))/(np.max(testX)-np.min(testX));
testY_min_max=(testY-np.min(testY))/(np.max(testY)-np.min(testY));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
训练集数据分布:
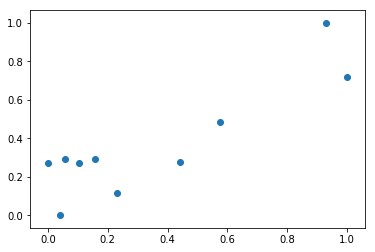
测试集数据分布:

训练部分代码:
import random
# 初始化回归相关参数值
a=random.random()# 随机初始化一个值
b=random.random()
c=random.random()
d=random.random()
e=random.random()
f=random.random()
g=random.random()
h=random.random()
x=trainX_min_max
y=trainY_min_max
lr=0.1# 学习率
iter=1000 # 训练次数
l=0.000001 # 正则化惩罚系数
cost=0
# 开始训练
for i in range(1,iter+1):
predict=a*np.power(x,7)+b*np.power(x,6)+c*np.power(x,5)+d*np.power(x,4)+e*np.power(x,3)+f*np.power(x,2)+g*x+h # 使用七次函数预测
# 计算损失函数
J=np.mean((predict-y)*(predict-y))
cost=np.append(cost,J)
# 计算损失函数的梯度值,这里加入了正则化
J_grad_a=np.mean((predict-y)*np.power(x,7))+l*a
J_grad_b=np.mean((predict-y)*np.power(x,6))+l*b
J_grad_c=np.mean((predict-y)*np.power(x,5))+l*c
J_grad_d=np.mean((predict-y)*np.power(x,4))+l*d
J_grad_e=np.mean((predict-y)*np.power(x,3))+l*e
J_grad_f=np.mean((predict-y)*np.power(x,2))+l*f
J_grad_g=np.mean((predict-y)*x)+l*g
J_grad_h=np.mean(predict-y)
# 进行参数迭代
a=a-lr*J_grad_a
b=b-lr*J_grad_b
c=c-lr*J_grad_c
d=d-lr*J_grad_d
e=e-lr*J_grad_e
f=f-lr*J_grad_f
g=g-lr*J_grad_g
h=h-lr*J_grad_h
# 打印参数的值
if i % 100 == 0:
print("iter=%d," % i)
print("cost=%.3f" % J)
print("a=%.3f," % a)
print("b=%.3f," % b)
print("c=%.3f," % c)
print("d=%.3f," % d)
print("e=%.3f," % e)
print("f=%.3f," % f)
print("g=%.3f," % g)
print("h=%.3f," % h)
print("\n")
plt.plot(cost)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
注意,我们在求偏导值的部分加入了正则化的代码,其中我们将2λ/m统一用常数l代替,并设置l的值,运行结果如图:
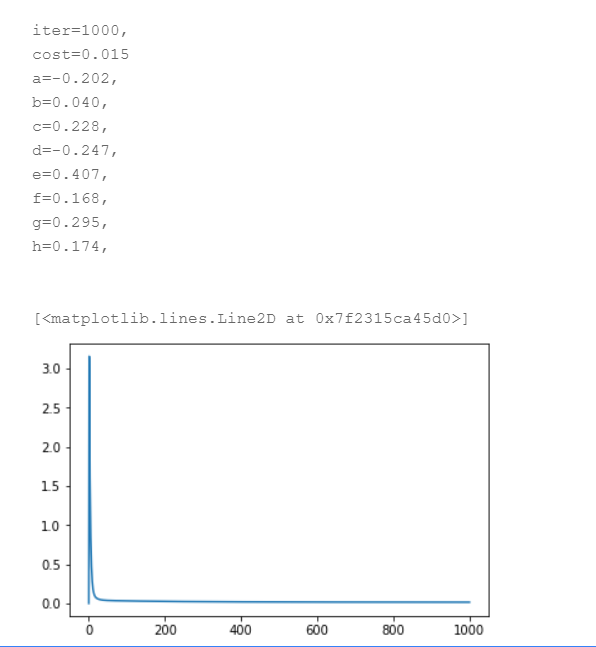
算法收敛,但是正确率为0.015,低于不加正则化时的结果,这是因为正则化对参数进行了惩罚,增加了模型的平滑度,降低了训练正确率。预测结果与真实数据对比:
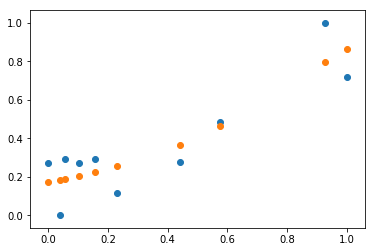
下面我们来看一下测试集的效果:
# 进行预测
x=testX_min_max
y=testY_min_max
result=predict=a*np.power(x,7)+b*np.power(x,6)+c*np.power(x,5)+d*np.power(x,4)+e*np.power(x,3)+f*np.power(x,2)+g*x+h
# 计算预测误差
err=np.mean((result-y)*(result-y))
# 打印误差
print('err=%.3f' % err)
# 绘制拟合结果
plt.scatter(x,y)
plt.scatter(testX_min_max,result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
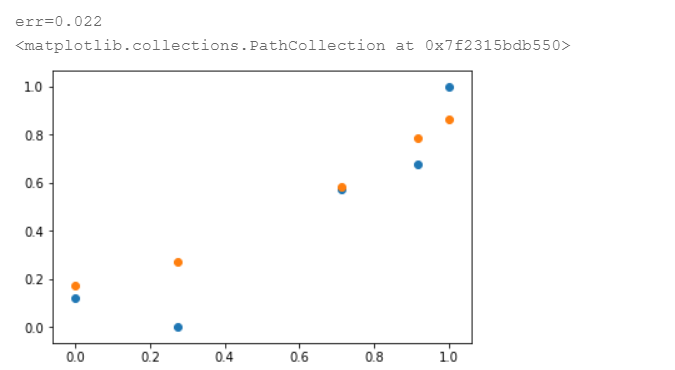
可以看出,正确率为0.022,确实优于不加正则化时测试集的效果,而且优于五次模型不加正则化处理的效果。所以说,加入正则化不仅保留了高次模型的优异性能(效果优于5次模型),同时提高模型的平滑度,抑制了过拟合现象,提升了模型的泛化能力。
下面我们来看一下增大λ,会发生什么事:
设置l为0.5,训练结果如下:
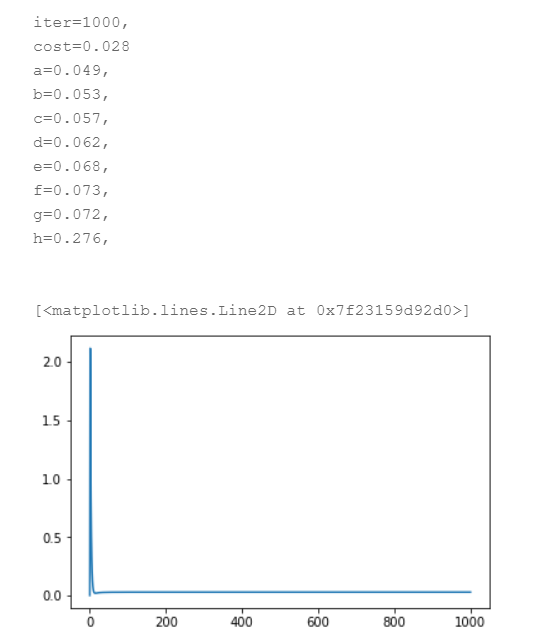

预测结果如下:

我们发现,当惩罚系数过大,拟合的函数将过于平滑,无论训练集还是测试集的正确率都会大幅下降。因此,我们要结合实际情况合理设置λ的值。
三、总结
本文介绍了过拟合现象的基本概念,产生原因以及解决方法。过拟合现象是指模型过于贴合训练集,从而导致其无法正确预测未知数据的现象,过拟合会导致模型的泛化能力差。过拟合现象的产生原因有两方面,一是训练数据过于简单,二是模型过于复杂。总的来说,就是模型的复杂度与训练集的复杂度不匹配。解决方法也可以从这两方面入手,即扩展数据集和简化模型。本文重点介绍了通过正则化处理来简化模型从而抑制过拟合现象的方法。从今天的实验也可以看出,扩展数据集后,即使不简化模型,最终的结果要优于正则化处理后的结果,因此,我们在条件允许的情况下,应该优先考虑采集尽可能多的数据以供我们的机器学习任务,这样才能从根部解决过拟合的问题。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5350次2021-06-07 09:28:15
-
浏览量:633次2023-10-08 10:23:23
-
2020-08-03 13:37:42
-
浏览量:9375次2017-11-25 15:52:31
-
浏览量:2419次2020-04-15 20:06:48
-
浏览量:4108次2020-03-03 22:19:33
-
浏览量:2790次2020-03-12 13:43:17
-
浏览量:3965次2020-12-21 19:41:54
-
浏览量:6278次2021-06-11 12:41:01
-
2020-03-26 16:21:16
-
浏览量:9756次2021-02-23 16:44:17
-
浏览量:1825次2023-05-05 14:55:59
-
浏览量:949次2024-01-22 16:42:18
-
浏览量:1518次2023-11-20 17:36:15
-
2023-07-05 10:11:14
-
浏览量:2365次2019-12-17 14:10:24
-
浏览量:174次2023-08-16 18:28:43
-
浏览量:4116次2020-11-20 19:06:57
-
浏览量:2807次2020-11-22 14:33:27






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
技术凯

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
