

硬核 | Sqoop入门指南
前言
我们在日常开发中需要经常接触到关系型数据库,如MySQL,Oracle等等,用它们来将处理后的数据进行存储。为了能够在Hadoop上分析这些数据,我们需要一些“工具”,将关系型数据库中的结构化数据存储到HDFS上。本篇文章,菌哥将介绍的一个操作最简单,同时也是在工作中使用频率极高的开源组件——Sqoop,希望您能在耐心看完之后,有所收获!

1、Sqoop简介
Sqoop全称是 Apache Sqoop,是一个开源工具,能够将数据从数据存储空间(数据仓库,系统文档存储空间,关系型数据库)导入 Hadoop 的 HDFS或列式数据库HBase,供 MapReduce 分析数据使用,也可以被 Hive 等工具使用。当 MapReduce 分析出结果数据后,Sqoop 可以将结果数据导出到数据存储空间,供其他客户端调用查看结果。
需要注意的是,数据传输的过程大部分是自动的,通过 MapReduce 过程来实现,只需要依赖数据库的Schema信息。Sqoop所执行的操作是并行的,数据传输性能高,具备较好的容错性,并且能够自动转换数据类型。
Sqoop存在两个版本,版本号分别是1.4.x和1.9.x,通常被称为Sqoop1和Sqoop2。Sqoop2在架构和实现上,对于Sqoop1做了比较大幅度的改进,因此两个版本之间是不兼容的。基于实际应用场景考虑,下面介绍的内容全都是基于Sqoop1的讲解。
2、Sqoop架构
Sqoop的出现使 Hadoop 或 HBase 和数据存储空间之间的数据导入/导出变得简单,这得益于Sqoop的优良架构特征和其对数据的强大转化能力。Sqoop 导入/导出数据可抽象为下图:

从图中可以看出,Sqoop作为 Hadoop 或 HBase 和数据存储空间之间的桥梁,很容易实现 Hadoop 或 HBase 和数据存储空间之间的数据传输。
Sqoop 的架构也非常简单,主要由3部分组成:Sqoop 客户端、数据存储与挖掘(HDFS/HBase/Hive)、数据存储空间,如图所示:

由图中可以看出,Sqoop协调 Hadoop 中的 Map 任务将数据从数据存储空间(数据仓库、系统文档、关系型数据库)导入 HDFS/HBase供数据分析使用,同时数据分析人员也可以使用 Hive 对这些数据进行挖掘。当分析、挖掘出有价值的结果数据之后,Sqoop 又可以协调 Hadoop 中的 Map 任务将结果数据导出到数据存储空间。
注意:Sqoop 只负责数据传输,不负责数据分析,所以只会涉及 Hadoop 的 Map 任务,不会涉及 Reduce 任务
3、Sqoop数据导入过程
Sqoop数据导入过程:从表中读取一行行数据记录,经过Sqoop的传输,再通过Hadoop的Map任务将数据写入HDFS,如图所示:
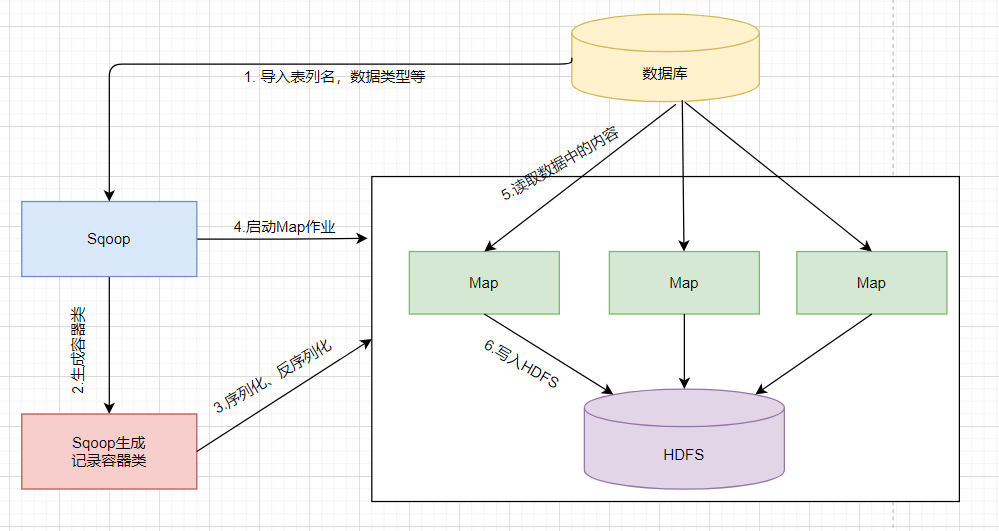
从图中可以看出,Sqoop数据导入过程如下:
(1)Sqoop通过JDBC获取所需要的数据库元数据信息,如表列名、数据类型等,并将这些元数据信息导入Sqoop。
(2)Sqoop生成一个与表名相同的记录容器类,记录容器类完成数据的序列化和反序列化过程,并保存表的每一行数据。
(3)Sqoop生成的记录容器类向Hadoop的Map作业提供序列化和反序列化的功能。
(4)Sqoop启动Hadoop的Map作业。
(5)Sqoop启动的Map作业在数据导入过程中,会通过JDBC读取数据库表中的内容,此时Sqoop生成的记录容器类同样提供反序列化功能。
(6)Map作业将读取的数据写入HDFS,此时Sqoop生成的记录容器类提供序列化功能。
4、Sqoop数据导出过程
Sqoop数据导出过程:将通过MapReduce或Hive分析后得出的数据结果导出到关系型数据库,供其他业务查看或生成报表使用,如图所示:

由图中可以看出,Sqoop数据导出过程如下:
(1)Sqoop读取数据库的元数据信息(包括数据表列名、数据类型等)
(2)Sqoop生成记录容器类,该类与数据库的表对应,提供序列化和反序列化功能。
(3)Sqoop生成的记录容器类为Map作业提供序列化和反序列化功能。
(4)Sqoop启动Hadoop的Map作业。
(5)Map作业读取HDFS中的数据,此时Sqoop生成的记录容器类提供反序列化功能。
(6)Map作业将读取的数据通过一批 INSERT 语句写入目标数据库中,每条 INSERT 语句都会批量插入多条记录。
5、Sqoop的安装和配置
Sqoop的安装非常简单,只需要简单的进行配置即可,下面简单介绍一下Sqoop的安装与配置。
注意:安装sqoop的前提是已经具备java和hadoop的环境
5.1 下载Sqoop
可以到Apache官网下载Sqoop
当然也可以在服务器的命令行输入以下命令进行下载Sqoop:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz5.2 安装并配置Sqoop
安装并配置Sqoop主要包括将Sqoop解压到指定的目录下,配置Sqoop系统的环境变量,修改Sqoop的配置文件,将所需要的数据库驱动复制到Sqoop的lib目录下。
(1)在命令行修改以下命令解压Sqoop,这里我解压的路径是/export/server
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz /export/server(2)修改Sqoop的环境变量
输入命令vim /etc/profile.d/sqoop.sh添加以下内容:
export SQOOP_HOME=/export/servers/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin(3)修改配置文件
进入到conf目录,修改文件名,然后编辑文件内容
cd $SQOOP_HOME/conf
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh这里我配置上Hadoop和Hive的信息
export HADOOP_COMMON_HOME= /export/servers/hadoop-2.7.5
export HADOOP_MAPRED_HOME= /export/servers/hadoop-2.7.5
export HIVE_HOME= /export/servers/hive(4)添加数据库驱动
我们将所需要的数据库驱动复制到Sqoop的lib目录下,如果你需要从SqlServer上进行抽取数据,那就需要添加SqlServer的相关jar包

然后将其复制到服务器上Sqoop的lib目录下。
(5)验证是否安装并配置成功
[cdp_etl@ellassay-cdh-utility-2 ~]$ sqoop version
21/01/24 14:22:27 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.16.2
Sqoop 1.4.6-cdh5.16.2
git commit id
Compiled by jenkins on Mon Jun 3 03:34:57 PDT 2019 当看到输出了Sqoop的版本,说明Sqoop的安装和配置就成功了!
6、Sqoop的使用
Sqoop的使用非常简单,只需要运行简单的命令即可实现将数据从数据库导入到HDFS,同时将数据分析结果从HDFS导出到数据库。
6.1 Sqoop的命令
想知道Sqoop有哪些命令,可以运行sqoop help命令,可以显示 Sqoop 所支持的所有命令信息,如下所示:
[alice@node01 ~]$ sqoop help
21/01/24 14:28:10 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.16.2
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command. 根据输出的提示信息,如果需要查看Sqoop具体的命令信息,可以使用sqoop help COMMAND命令。下面我们以export命令为例,如下所示:
[alice@node01 ~]$ sqoop help export
21/01/24 14:30:17 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.16.2
usage: sqoop export [GENERIC-ARGS] [TOOL-ARGS]
Common arguments:
--connect <jdbc-uri> Specify JDBC
connect
string
--connection-manager <class-name> Specify
connection
manager
class name
--connection-param-file <properties-file> Specify
connection
parameters
file
--driver <class-name> Manually
specify JDBC
driver class
to use
--hadoop-home <hdir> Override
$HADOOP_MAPR
ED_HOME_ARG
--hadoop-mapred-home <dir> Override
$HADOOP_MAPR
ED_HOME_ARG
--help Print usage
instructions
--metadata-transaction-isolation-level <isolationlevel> Defines the
transaction
isolation
level for
metadata
queries. For
more details
check
java.sql.Con
nection
javadoc or
the JDBC
specificaito
n
--oracle-escaping-disabled <boolean> Disable the
escaping
mechanism of
the
Oracle/OraOo
p connection
managers
-P Read
password
from console
--password <password> Set
authenticati
on password
--password-alias <password-alias> Credential
provider
password
alias
--password-file <password-file> Set
authenticati
on password
file path
--relaxed-isolation Use
read-uncommi
tted
isolation
for imports
--skip-dist-cache Skip copying
jars to
distributed
cache
--temporary-rootdir <rootdir> Defines the
temporary
root
directory
for the
import
--throw-on-error Rethrow a
RuntimeExcep
tion on
error
occurred
during the
job
--username <username> Set
authenticati
on username
--verbose Print more
information
while
working
....
Generic Hadoop command-line arguments:
(must preceed any tool-specific arguments)
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
At minimum, you must specify --connect, --export-dir, and --table 可以看到列出了export命令的使用格式和参数信息。
如果我们想将数据从数据存储空间导入到HDFS,那么我们就需要使用import命令:
其中import命令常用的参数如下:

为了方便大家理解,下面我将通过一个例子来使用Sqoop
7、Sqoop的使用
7.1 全量导入MySQL的数据到HDFS
现在在MySQL的userdb数据库下有一张 emp 表,需要将表数据的内容全量导入到HDFS

我们就只需要执行下面的Sqoop命令即可
bin/sqoop import \
--connect jdbc:mysql://192.168.100.100:3306/userdb \
--username root \
--password hadoop \
--delete-target-dir \
--target-dir /sqoopresult \
--table emp --m 1 其中 --target-dir 可以用来指定导出数据存放至HDFS的目录
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据:
hdfs dfs -cat /sqoopresult/part-m-00000
7369,SMITH,CLERK,7902,1980-12-17,800,,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,,20
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,,10
7788,SCOTT,ANALYST,7566,1987-04-19,3000,,20
7839,KING,PRESIDENT,,1981-11-17,5000,,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30 可以看出它会在HDFS上默认用逗号,分隔emp表的数据和字段。当然我们也可以通过--fields-terminated-by '\t'来指定导出的分隔符
7.2 导入子数据集到HDFS
上面我们导入的是全量的数据,很多时候,我们需要对数据进行过滤处理,导入的是原始数据的一个子数据集,那该怎么办呢?这里提供2种方式:
7.2.1 3.where过滤
--where可以指定从关系数据库导入数据时的查询条件。它执行在数据库服务器相应的SQL查询,并将结果存储在 HDFS 的目标目录。
bin/sqoop import \
--connect jdbc:mysql://192.168.100.100:3306/sqoopdb \
--username root \
--password hadoop \
--where "sex ='male'" \
--target-dir /wherequery \
--table employee --m 17.2.1.4 query查询
需要注意:使用query sql语句来进行查找不能加参数--table ;并且必须要添加where条件;where条件后面必须带一个$CONDITIONS 这个字符串;且这个sql语句必须用单引号,不能用双引号。
bin/sqoop import \
--connect jdbc:mysql://node-1:3306/userdb \
--username root \
--password hadoop \
--target-dir /wherequery12 \
--query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\t' \
--m 2 sqoop命令中,--split-by id通常配合-m 参数使用。用于指定根据哪个字段进行划分并启动多少个maptask。
注意,当 -m 设置的值大于1时,split-by必须设置字段,且只能是int类型
另外,关于--split-by参数的深入理解大有学问:
1、split-by 根据不同的参数类型有不同的切分方法,如 int 型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来 确定划分几个区域。比如 select max(split_by),min(split-by) from 得到的 max(split-by)和min(split-by) 分别为1000和1,而num-mappers(-m)为2的话,则会分成两个区域 (1,500)和(501-1000),同时也会分成2个sql给2个map去进行导入操作,最后每个map各自获取各自SQL中的数据进行导入工作。
2、split-by即便是int型,若不是连续有规律递增的话,各个map分配的数据是不均衡的,可能会有些map很忙,有些map几乎没有数据处理的情况,就容易出现数据倾斜,所以一般split by的值为自增主键id。
巨人的肩膀
1、《海量数据处理与大数据实践》
2、https://www.cnblogs.com/pejsidney/p/8962302.html
3、《开源组件系列:关系型数据导入(Sqoop与Canal)》
小结
本篇文章主要从架构的角度出发,让大家理解Sqoop的数据导入/导出的详细过程,并学会Sqoop的安装配置与常用命令,最后通过一个小的实践为大家展示了Sqoop的使用。但篇幅有限,无法将其所有的“精华”都悉数奉献给大家,像Sqoop的增量导入,更新导出,Sqoop job,只能让小伙伴们自行去探索,而对于一个大数据开发者,使用Sqoop所踩的一些“坑”,我也很乐意在某一期文章分享给大家。好了,本篇文章就到这里,如果对您有所帮助,请帮忙一键三连,分享给更多的朋友。你知道的越多,你不知道的也越多,我是Alice,我们下一期见!

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6318次2020-02-06 11:21:54
-
浏览量:2866次2019-05-24 10:33:32
-
浏览量:11748次2019-02-16 11:31:35
-
浏览量:5033次2019-09-23 16:58:01
-
浏览量:2444次2024-03-29 10:57:19
-
浏览量:6905次2020-08-19 14:55:13
-
浏览量:3920次2020-08-18 20:09:59
-
浏览量:1788次2018-12-19 10:11:25
-
浏览量:1804次2023-07-27 10:28:36
-
浏览量:2178次2019-12-03 16:21:12
-
浏览量:2287次2020-08-18 19:54:52
-
浏览量:2127次2018-12-19 09:52:55
-
浏览量:5791次2024-03-14 14:15:25
-
浏览量:2213次2022-11-30 09:49:56
-
浏览量:1308次2024-12-10 13:54:25
-
浏览量:2985次2024-03-29 11:08:20
-
浏览量:10968次2020-12-17 18:02:15
-
浏览量:3494次2020-07-13 17:40:25
-
浏览量:2493次2022-02-11 09:00:24
大数据梦想家
一枚有趣的程序员,更多精彩内容请移步公众号@大数据梦想家

-
8篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
大数据梦想家

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
