

口罩佩戴检测(三):分类器设计
在进行完数据降维后,我们将设计svm支持向量机作为分类器
一、为何选用SVM:
首先相较于人工神经网络,支持向量机解决的是一个有线性约束的二次优化问题,有唯一的最优解。2、其次对于口罩识别问题我们最关心的是分类器的推广能力(generalization)。支持向量机能够在样本数先对较少且特征维数很高的情况下实现很好的推广性。3、图像向量维度很高,支持向量机可以采用核函数方法避免高维度运算。
对于理解模式识别所学习的知识方面:
SVM有线性分类器和非线性分类器。SVM使我们在实践过程中更好的理解两类分类器的特点。
为何SVM会有更好的推广度和泛化能力:
对于训练集在某个w下对所有训练样本的分类决策损失就是Remp,也叫做经验风险。
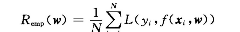
我们更关心的是对于测试集在权值w下对未知样本的预测风险,我们用期望风险来衡量。
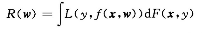
由Vapnik等提出的统计学习理论表明,期望风险和经验风险满足下列关系:
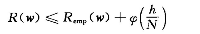
机器学习算法复杂度越低,二者差距就会越小,推广能力就会越好。
Remp容易实现为0 在样本N给定的情况下,唯一的办法是调整VC维(h)。
在统计学中对于规范化的分类超平面,如果权值满足||w||< A常数,则存在VC维存在上界,
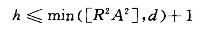
样本规定后,d和R^ 2是固定的。最小的A等价于求最大分类间隔。所以支持向量机的最大间隔准则是通过控制算法的VC维实现最好的推广能力,所以我们在该问题中优先考虑使用SVM。
通过简单分析,该模式识别问题基本符合线性可分的条件。故我们希望找到一个最优的超平面满足对该问题的样本分类且鲁棒性最好。
二、分类器原理及设计
(1)线性SVM:
分类决策函数选择符号函数:
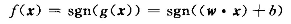
满足下列条件表示超平面没有错误的条件:
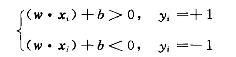

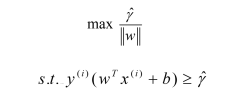
但是上式是个非凸性约束问题,为了求解我们做出通过添加约束条件来将该问题变为凸优化问题。
由于符号函数尺度调整不会影响分类决策,故为了方便求解我们对尺度进行调整:
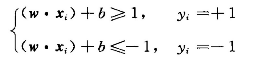
故分类正确的样本可以表示为(目的是为了简化后面的拉格朗日优化问题:支持向量满足等号成立条件)
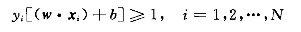
支持向量间距:

问题转化为凸优化问题。

对于该问题可直接通过QP或者相关软件求解;但是考虑到计算成本和问题本身的特殊性,我们可以通过对该问题等价对偶问题的求解得到该问题的解。
故对每个样本引入拉格朗日系数等价转换为下面问题的解。
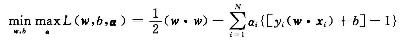
先固定α,分别对W和b求偏导数得到
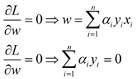
带入原方程后等价对偶问题为:
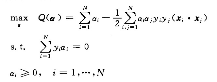
通过matlab的二次规划程序求得ai,然后可得到

进一步解释b的求解:由于该优化问题的解在鞍点上取得,由于
鞍点上的点都满足:

所以那些非支持向量的ai必为零。
求b只能对于支持向量带入该公式求解。
但是往往人们通过对所有支持向量通过求解b*后取平均得到。
上式即为最优超平面的解。
(2) 样本点不能满足线性可分情况下引入松弛因子
若不能满足严格和线性可分则引入松弛因子并加入惩罚项使得松弛因子之和尽可能小。松弛因子不是对所有样本都加,加最小的松弛因子使得所有样本点满足
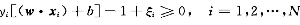
则目标函数变为:
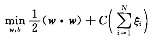
其中C的较小强调正确分类的间隔,C较大强调分类错误的惩罚。
这个目标函数反映了我们两个期望:一方面希望分类间隔尽可能的大,另一方面希望错分样本数尽可能少。
同严格线性可分,对偶优化问题转化为下列问题:
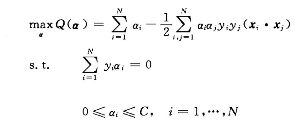
多了一个约束条件α的上界限C。
得到ai之后通过下列表达式求出超平面得到最终解。
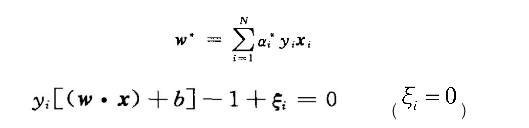

(3)SVM线性分类器:(SVM的核函数方法)
当样本在原始空间无法线性可分时可以将样本点映射到更高维度的空间中,有可能实现在更加高纬度存在超平面可以将样本无错误分类。因为理论上维度增加到无限维度时候一定可以对任意某两类样本无错误分类(例如只从腿的数量和是否哺乳动物可能无法区分猫和狗,故增加维度,判断颅骨形状特征和习性则可以区分开两类。)
但是当引入广义线性判别函数的时候新的特征共空间的维度极大增加了,导致维数灾难(1维度增加计算量过于复杂,分类计算成本过高;2当样本数目一定映射到高纬度空间,样本点之间变得稀疏,容易产生病态矩阵不利于问题的解决)
假设我们把原始样本空间Xi通过一种非线性变换到高纬空间。然后再高维空间中构造支持向量机。得到新特征空间内的支持向量机决策函数:
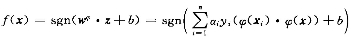
同理其中αi可以通过对下面的二次优化问题的解:
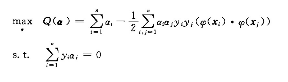

如通过对线性可分条件下得到的支持向量机的判别函数我们可以发现原空间中的解和高维空间的解唯一区别是原始空间中的内积转换为新空间中的内积,但是新空间中的内积仍然是原始空间样本点的函数。所以定义新的函数:

所以原本的优化问题和高维空间的支持向量机可以直接用低维样本表示:

但是注意这里的ai已经发生了变化因为优化对偶问题的空间变化了:
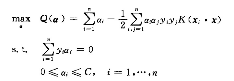
B的求解仍然对于支持向量通过下式求得:
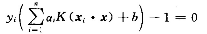
对于此问题我们通过对各种常用核函数的对比最终选择了线性核函数。(核函数RBF来达到映射后空间的无限维,从宽度较大的核开始累试最终达到期望分类效果。但是效果并不理想)
三、SVM分类器的实现
1、导入数据并处理
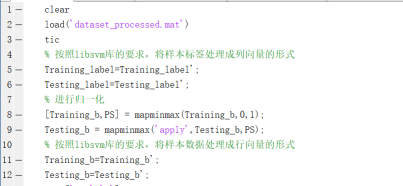
2、使用libsvm库分类并预测
(1)线性核


输出结果:

(2)多项式核


输出结果:

(3)RBF核


输出结果:
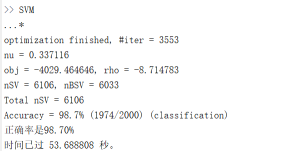
(4)sigmoid核
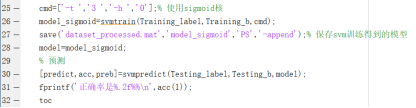
输出结果:

3、不同核函数影响分类结果对比总结
总结:

比较svm的三个核函数以及线性核,我们发现:线性核的效果最好,仅用了31s,RBF核与sigmoid核性能不相上下,多项式核效果最差,无论是正确率还是运行时长。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6675次2021-01-08 02:27:20
-
浏览量:229次2023-08-03 15:44:04
-
浏览量:5745次2021-01-08 03:12:37
-
浏览量:9677次2021-01-08 01:26:48
-
浏览量:1547次2024-02-18 14:24:39
-
浏览量:6280次2021-07-09 11:16:51
-
浏览量:5389次2020-12-24 22:06:12
-
浏览量:12549次2021-01-29 12:25:06
-
浏览量:14531次2020-12-20 20:19:00
-
浏览量:2398次2020-07-03 14:08:01
-
浏览量:7289次2020-12-20 19:38:14
-
浏览量:927次2023-09-25 14:19:19
-
浏览量:7328次2020-12-24 23:03:55
-
浏览量:2269次2019-07-01 10:40:05
-
浏览量:966次2023-03-09 09:14:06
-
浏览量:2276次2020-05-14 10:34:23
-
浏览量:2291次2020-04-11 10:22:37
-
浏览量:986次2023-04-21 10:46:52
-
浏览量:2689次2022-03-08 09:00:11






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
技术凯

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
