

模式识别之数据降维(四):SFS方法效果测试
上篇文章,我们介绍了SFS的基本原理以及matlab的具体实现,并成功选择了40个特征,这篇文章,我们将使用这40个特征进行分类,测试SFS方法的效果。
一、二分类测试
我们去除二分类样本数据中的无关特征,仅保留SFS选择的40个特征,使用bayes分类器进行分类,观察最终的正确率,测试SFS的性能,使用的数据集以及测试方法和第二讲相同(链接)。具体实现如下:
(1)读取数据集,计算先验概率

(2)去除训练集和测试集的无关特征,仅保留最优的40个特征

(3)使用bayes算法进行分类

完整代码如下:
clear
load('2-Class Problem.mat');
load('feature_selected_SFS');
tic
%获取训练数量
n1=size(Training_class1,2);
n2=size(Training_class2,2);
% 先验概率
pw1=n1/(n1+n2);
pw2=n2/(n1+n2);
dim=size(Training_class1,1);%维数
Training_data1=Training_class1(feature_selected,:);
Training_data2=Training_class2(feature_selected,:);
Testing_data=Testing(feature_selected,:);
%参数估计
[miu1,sigma1]=ParamerEstimation(Training_data1);
[miu2,sigma2]=ParamerEstimation(Training_data2);
%预测结果
predict_label=0;
test_num=size(Testing,2);%获取测试数据数量
for i=1:test_num
x=Testing_data(:,i);
pxw1=gaussian(miu1,sigma1,x);
pxw2=gaussian(miu2,sigma2,x);
if pw1*pxw1>pw2*pxw2
predict_label(i)=1;
else
predict_label(i)=2;
end
end
% 计算精度
acc=sum(predict_label==Label_Testing)/test_num;
fprintf('正确率是%.2f%%\n',acc*100);
toc
程序运行结果分析:

仅用SFS方法选择的40个特征进行分类就可以达到100%的正确率,而且大大节省了程序运行时间。
二、多分类测试
和二分类一样,去除无关特征,仅保留40个最优特征进行多分类测试,数据集与第二讲相同(链接)
(1)获取数据集,处理数据集,去除无关特征,只保留已选择的40个特征
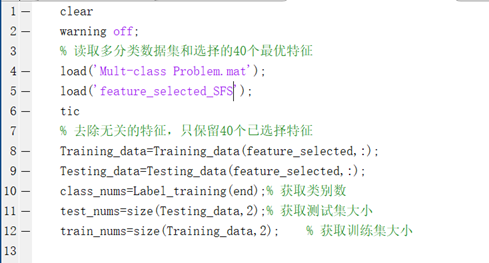
(2)使用bayes对含有40个特征的测试数据进行多分类

完整代码如下:
clear
warning off;
% 读取多分类数据集和选择的40个最优特征
load('Mult-class Problem.mat');
load('feature_selected_SFS');
tic
% 去除无关的特征,只保留40个已选择特征
Training_data=Training_data(feature_selected,:);
Testing_data=Testing_data(feature_selected,:);
class_nums=Label_training(end);% 获取类别数
test_nums=size(Testing_data,2);% 获取测试集大小
train_nums=size(Training_data,2); % 获取训练集大小
Training_temp=0;
predict=0;
for class=1:class_nums
[miu(:,class),sigma(:,:,class)]=ParamerEstimation(Training_data(:,Label_training==class));
num=size(Training_data(:,Label_training==class),2);
pw(class)=num/train_nums;% 计算先验概率
end
for i=1:test_nums
for class=1:class_nums
% 计算类的条件概率密度
pxw(class)=gaussian(miu(:,class),sigma(:,:,class),Testing_data(:,i));
% 计算判别式
g_x(class)=log(pw(class))+log(pxw(class));
end
[~,argmax]=max(g_x);
predict(i)=argmax;
if mod(i,100) == 0
acc=sum(predict==Label_testing(1:i))/(i);
disp(['预测数据号:' num2str(i)])
disp(['准确度是:' num2str(acc)])
end
end
acc=sum(predict==Label_testing)/(test_nums);
toc
disp(['总准确度是:' num2str(acc)]) 程序运行结果:
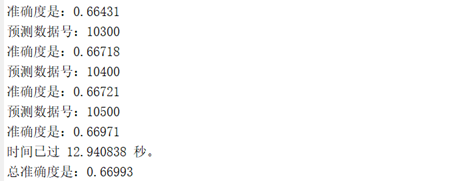
时间用了13s,正确率为66.9%。
三、总结
本篇文章测试了SFS方法选择的特征对于分类的性能,可以看出,二分类和多分类都能够维持良好的正确率,并且大大降低了程序运行时间。通过对比第二讲(链接),我们发现SFS方法和遗传算法选择的特征对于二分类来说没有什么区别,但是遗传算法选择出来的特征对于多分类来说,正确率和运行速度两方面都略优于SFS方法。聪明的读者可能已经发现SFS方法的缺陷了,正如第三讲所讲,SFS是从第一个特征开始选择,之后所有的特征都是与之前选择的特征组合起来进行对比分析,比如我们要从特征a、b、c中选择两个特征,已经选择好第一个最优特征为a,现在选择第二个特征,那么第二轮选择的特征只可能是ab、ac的组合,那就有可能丢弃了最优的组合bc,这便是SFS方法的缺陷。工程师们后来对SFS方法进行了改进,提出了SFBS(Sequential Forward Backward Selection)方法,加入了反向搜索的过程,扩大了特征选择的范围。
至此,特征选择的相关内容已经介绍完毕,之后的文章,我们将介绍特征提取相关内容。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:14899次2020-12-29 15:13:12
-
浏览量:20085次2020-12-31 17:28:23
-
浏览量:10290次2020-12-31 13:45:15
-
浏览量:8280次2020-12-27 09:50:29
-
浏览量:14663次2020-12-27 09:15:43
-
浏览量:6551次2021-06-11 10:08:48
-
浏览量:6675次2021-01-08 02:27:20
-
浏览量:18856次2021-01-08 01:48:55
-
浏览量:14712次2021-01-08 03:03:13
-
浏览量:1635次2023-02-21 09:02:46
-
浏览量:7343次2021-01-08 02:45:30
-
浏览量:5984次2021-04-20 15:43:03
-
浏览量:1402次2023-06-03 16:05:52
-
浏览量:3716次2019-09-18 22:22:32
-
浏览量:14531次2020-12-20 20:19:00
-
浏览量:2306次2018-01-29 23:03:32
-
浏览量:6157次2021-05-02 18:00:46
-
浏览量:838次2023-06-03 15:58:33
-
浏览量:8349次2020-12-19 15:06:30






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
技术凯

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
