

贝叶斯分类器之使用最小错误贝叶斯决策进行二分类
一、前言
在之前的一篇文章贝叶斯分类器之统计决策方法和概率密度估计中,我们介绍了统计决策方法以及贝叶斯分类的概率密度估计,这篇文章,我们将使用之前介绍的概率密度的几种方法,进行实战,并观察它们之间的差别。
二、使用参数估计方法
这一部分,我们已经在之前的一篇文章《贝叶斯二分类算法的实现》中实现了,下面只贴出代码以及运行结果。
源代码:
file_name='2-Class data.mat';
load(file_name);
t1=clock;% 开始计时
Training_class1=Training(:,Label_Training==1);% 第一类数据
Training_class2=Training(:,Label_Training==2);% 第二类数据
% 获取两类训练数据的数量与维度,b1、b2是维度,n1、n2是数量
[b1,n1]=size(Training_class1);
[b2,n2]=size(Training_class2);
% 获取测试数据的数量和维度
[b,n]=size(Testing);
% 先验概率
pw1=n1/(n1+n2);
pw2=n2/(n1+n2);
% 概率密度估计,参数估计
[miu1,sigma1]=ParamerEstimation(Training_class1);
[miu2,sigma2]=ParamerEstimation(Training_class2);
% 初始化预测结果
predict_label=0;
for i=1:n
x=Testing(:,i);
% 概率密度估计
pxw1=gaussian(miu1,sigma1,x);
pxw2=gaussian(miu2,sigma2,x);
% 判别函数
g_x1=pw1*pxw1;
g_x2=pw2*pxw2;
if g_x1>g_x2
predict_label(i)=1;
else
predict_label(i)=2;
end
end
% 计算正确率
acc=sum(predict_label==Label_Testing)/n;
t2=clock;% 结束计时
time=etime(t2,t1);
fprintf('正确率是%.2f%%\n',acc*100);
fprintf('运行时长是%.2fs\n',time);运行结果:

三、使用非参数估计方法
a. Parzen窗法
编程思路:首先需要对数据进行等比例缩小,防止因数据过大,在计算小舱体积时发生溢出。其余思路与参数估计方法类似,只是类的条件概率使用Parzen窗法进行估计,Parzen窗采用方窗,小窗边长取1。
代码如下:
(1)导入数据并对数据进行处理,防止运算过程中发生溢出
clear
load('2-class Problem.mat');
tic
% 数据缩放,防止溢出
Training_class1=Training_class1/100;
Training_class2=Training_class2/100;
Testing=Testing/100;(2)获取数据集信息(数量、维度等),并计算先验概率
% 获取数据集相关信息
[d1,n1]=size(Training_class1);
[d2,n2]=size(Training_class2);
[d,n]=size(Testing);
% 先验概率
pw1=n1/(n1+n2);
pw2=n2/(n1+n2);(3)遍历测试样本数据,对每个数据进行分类
for i=1:n
x=Testing(:,i);
%用方窗:
if pw1*Parzen(x,1,Training_class1)>pw2*Parzen(x,1,Training_class2)
predict(i)=1;
else
predict(i)=2;
end
end(4)计算正确率
acc=sum(predict==Label_Testing(1:n))/n;
toc
fprintf('正确率是%.2f%%\n',acc*100);运行结果分析:使用Parzen窗法进行非参数估计可以直接估计概率密度,而不用估计相关参数,与参数估计方法相比,大大降低了运行时间,而且保证了二分类的正确率。
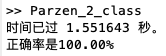
完整代码如下:
clear
load('2-class Problem.mat');
tic
% 数据缩放,防止溢出
Training_class1=Training_class1/100;
Training_class2=Training_class2/100;
Testing=Testing/100;
% 获取数据集相关信息
[d1,n1]=size(Training_class1);
[d2,n2]=size(Training_class2);
[d,n]=size(Testing);
% 先验概率
pw1=n1/(n1+n2);
pw2=n2/(n1+n2);
predict=0;
for i=1:n
x=Testing(:,i);
%用方窗:
if pw1*Parzen(x,1,Training_class1)>pw2*Parzen(x,1,Training_class2)
predict(i)=1;
else
predict(i)=2;
end
end
acc=sum(predict==Label_Testing(1:n))/n;
toc
fprintf('正确率是%.2f%%\n',acc*100);b.近邻法
编程思路:编程实现与使用Parzen窗法程序类似,只是在估计类的条件概率时,使用近邻法。N取2.
源代码:
clear
load('2-class Problem.mat');
tic
% 数据缩放,防止溢出
Training_class1=Training_class1/100;
Training_class2=Training_class2/100;
Testing=Testing/100;
% 获取数据集相关信息
[d1,n1]=size(Training_class1);
[d2,n2]=size(Training_class2);
[d,n]=size(Testing);
% 先验概率
pw1=n1/(n1+n2);
pw2=n2/(n1+n2);
predict=0;
for i=1:n
x=Testing(:,i);
if pw1*KNN(x,2,Training_class1)>pw2*KNN(x,2,Training_class2)
predict(i)=1;
else
predict(i)=2;
end
end
acc=sum(predict==Label_Testing(1:n))/n;
toc
fprintf('正确率是%.2f%%\n',acc*100);运行结果分析:二分类中,使用近邻法的程序运行效率高于Parzen窗法,而且可以保证100%的正确率。
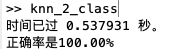
四、总结
本文对比了使用最小错误贝叶斯分类器进行二分类决策时,采用不同方法进行概率密度估计的差异,发现所有概率密度估计方法都能达到100%的正确率,且非参数估计效率高于参数估计方法,这是因为非参数估计不需要任何参数就可以进行类的条件概率的估计,相比于概率密度估计方法,省去了估计参数的步骤。此外,非参数估计方法不受限于样本服从的分布类型。但是聪明的读者或许已经察觉到问题了,我们在之前的文章中讲过,我们使用的二分类样本实际上是线性可分的,所以,我们使用这些方法都可以达到完全正确的分类结果。因此,在实际中,非参数估计或许效率较高,但是分类正确率方面不一定比参数估计优异。因此,在接下来的文章中,我们将进行多分类的决策,到那时,样本将会是线性不可分的,我们将再一次比较参数估计与非参数估计的性能,大家拭目以待。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:11595次2020-12-18 00:50:25
-
浏览量:8349次2020-12-19 15:06:30
-
浏览量:7307次2020-12-20 16:38:21
-
浏览量:4667次2021-06-30 11:34:00
-
浏览量:14899次2020-12-29 15:13:12
-
浏览量:6355次2020-12-20 16:30:48
-
浏览量:6193次2021-04-14 16:24:29
-
浏览量:1904次2023-09-05 18:20:58
-
浏览量:1072次2023-07-05 10:16:00
-
浏览量:20085次2020-12-31 17:28:23
-
浏览量:5984次2021-04-20 15:43:03
-
浏览量:8280次2020-12-27 09:50:29
-
浏览量:4593次2021-05-25 16:44:59
-
浏览量:891次2023-09-28 11:19:15
-
浏览量:10290次2020-12-31 13:45:15
-
浏览量:7289次2020-12-20 19:38:14
-
浏览量:1244次2023-01-12 15:13:42
-
浏览量:14531次2020-12-20 20:19:00
-
浏览量:4336次2021-07-01 16:36:28






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
技术凯

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
