

快速获取一个网站所有资源
有时候我们需要分析一个网站,或者基于一个网站进行魔改,这个就需要一些特殊的手段将网站源码下载到本地了,其实目前大部分网站都是有代码压缩的,很难去有修改。
这里我就教大家如何快速获取一个网站的所有资源,包括源码,图片,js,css。
以这个页面为例
https://loading.io/spinner/
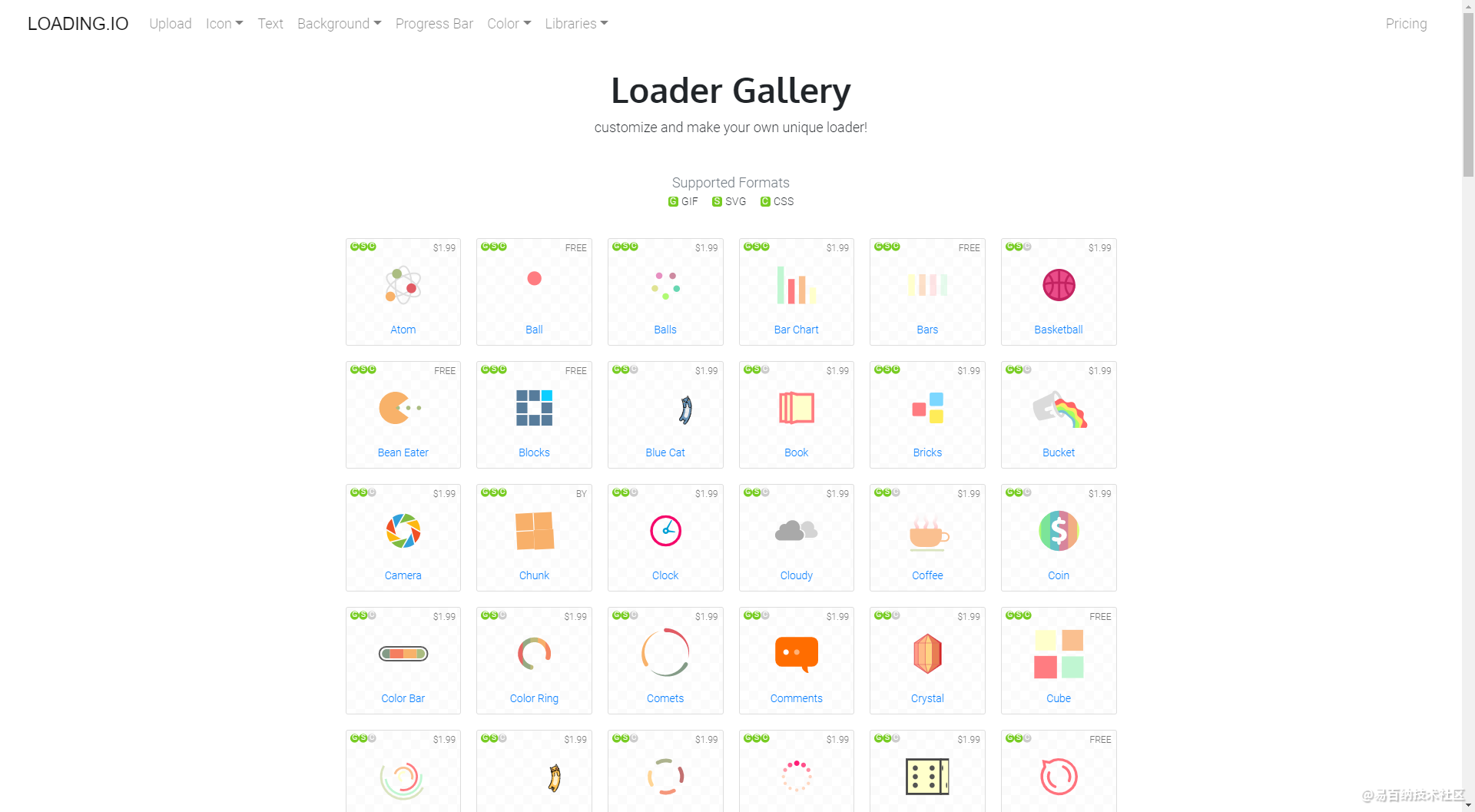
这个页面所显示的图标都是付费的,但我们可以通过一些简单的手段将所有资源下载到本地。其实这并不是什么神奇的技能,有需求,就有供应,就有牛逼的程序来教你做事。
第一种CTRL+S
浏览器打开https://loading.io/spinner/, 按下 CTRL+S, 选择一个保存网站的目录,并且保存类型 选择 网页,全部(.htm, .html )
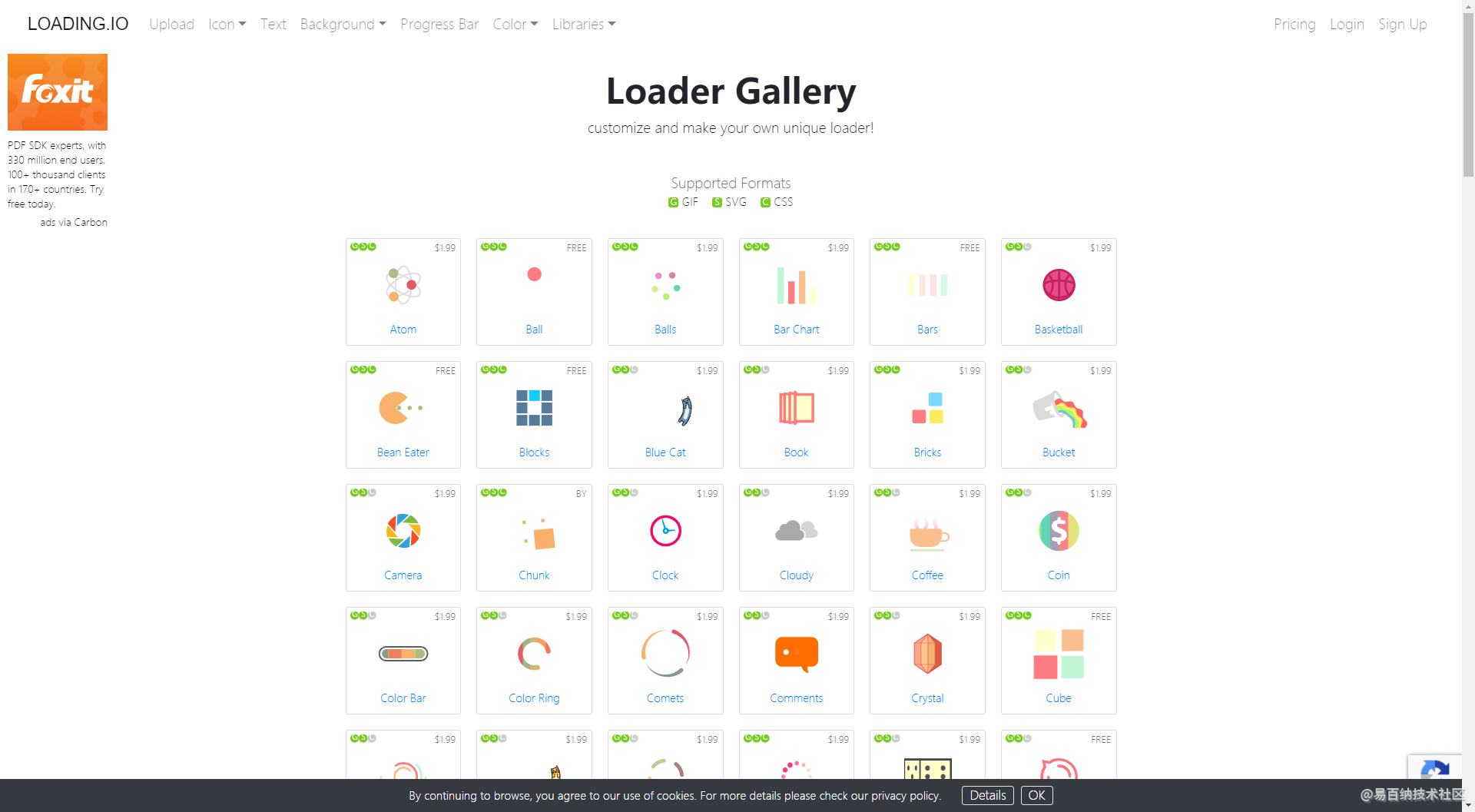
待下载完成后,打开,和原网站相差无几。这个页面所有的资源都保存在了你选择的文件目录里。想要那个图片,svg都可以直接拿去用。是不是很方便。另外需要注意的时候,打开页面的时候最好用http协议打开,以为有些网站不能在file协议下访问。
如果你打算将这个页面,修改完善,当做一个系统的一部分。这里我提供一个修改,优化的思路。
首先要将js挑拣出来,引入了几个包,每个包都是干嘛的,能否去掉,查看控制台,报错显示是那个js报的,能否去掉。有些页面,完全不需要js,只用html和css就能和网站长得一样。我改过很多个网站。
下载后访问效果
第二种使用Cyotek WebCopy软件
Cyotek WebCopy是一个免费的分析网站拓扑资源图,并提供下载全站资源的功能的软件。非常好用,之前我也用过很多下载网站的,都不如它好。下载地址 https://www.cyotek.com/cyotek-webcopy
下载后一键安装,然后将网站的主页输入,点击开始,程序就能自动分析网站的资源引用关系,并且创建好目录,分门别类下载到对应的文件夹中。你根本不用修改html的资源引用路径。

点击旁边的Scan 可以对整个网站的资源进行分析。分析后的资源图
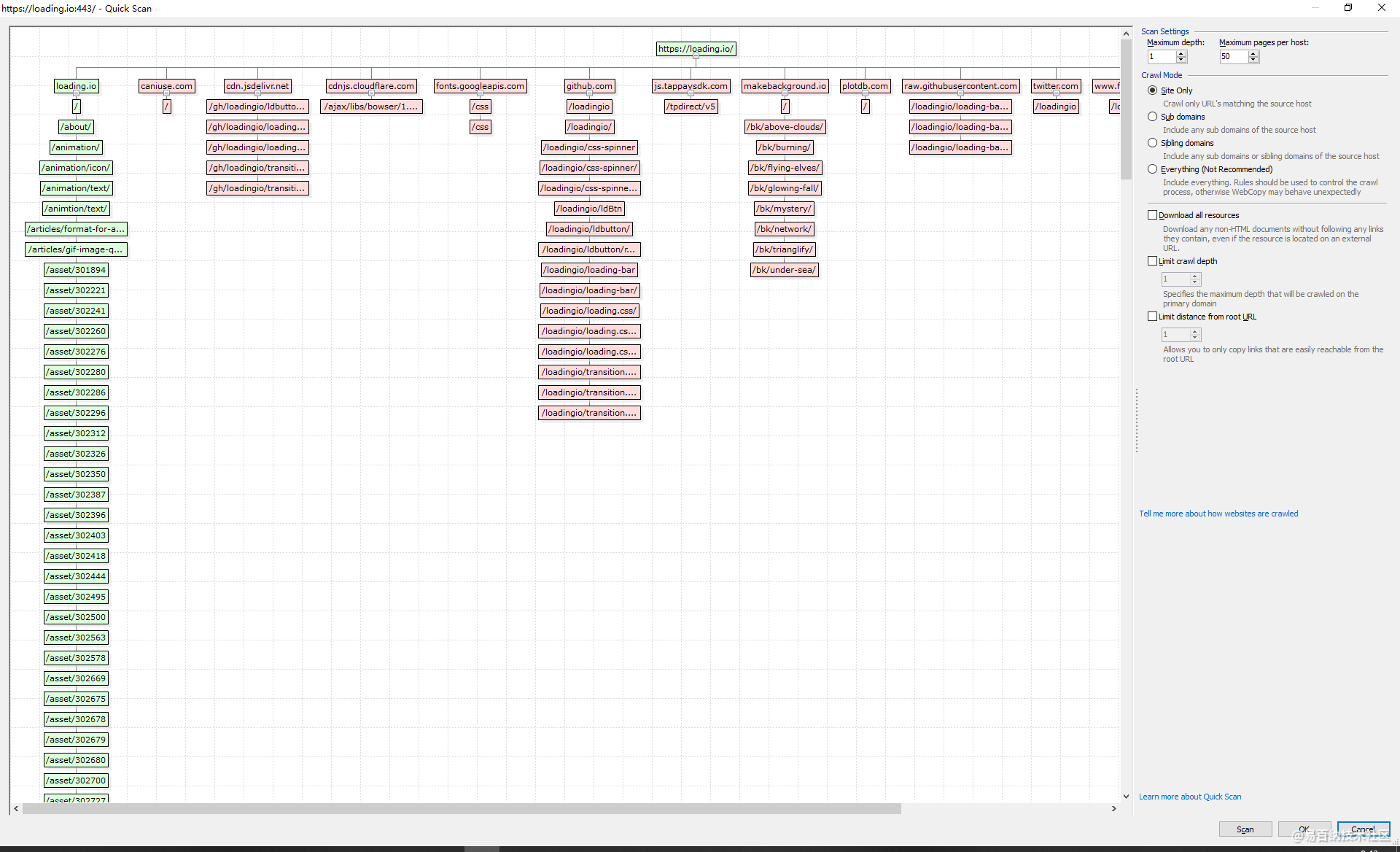
因为一个网站资源可能会有其他域名的,你可以在这里选择,将一些其他域名的资源排除,或者爬取。如果第一次爬取效果不好的话,可以尝试将所有资源加入扒取列表。
下载整个网站的资源,过程是漫长的。你可以砌杯咖啡,慢慢等待。有时候你不用等程序下载完成。
下载完成后,直接将整个文件夹放到web服务器里,就能访问了,链接,图片很多交互,程序都帮你处理好了。
下载后,可能会有多个一个页面,可能会存在多个html,你需要找到效果最好的一个页面作为首页
下面是爬取后的展示
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
-
浏览量:2964次2020-08-03 13:36:13
-
浏览量:2628次2022-03-22 09:00:12
-
浏览量:3139次2020-11-03 10:19:23
-
浏览量:7210次2022-05-30 15:26:15
-
浏览量:793次2025-03-08 11:24:40
-
浏览量:2425次2020-08-14 18:15:32
-
浏览量:2714次2023-04-12 18:08:59
-
浏览量:1912次2023-04-12 18:41:04
-
浏览量:428次2025-03-05 14:40:45
-
2023-02-15 10:31:45
-
浏览量:4724次2021-08-26 14:50:36
-
浏览量:928次2023-10-08 17:57:29
-
浏览量:15776次2020-12-03 22:52:27
-
浏览量:1419次2023-10-25 18:39:50
-
浏览量:4530次2021-07-19 18:05:51
-
浏览量:1010次2023-10-24 17:47:15
-
浏览量:6166次2021-08-04 13:46:28
-
浏览量:2325次2018-12-19 12:36:45
-
浏览量:719次2025-09-23 11:49:45

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820

是的,很好用的一个软件。
这个初学者利器~