

基于 flink 的电商用户行为数据分析【5】| 基于埋点日志数据的网络流量统计
前言
在《基于flink的电商用户行为数据分析【3】| 实时流量统计》这篇文章中,博主为大家介绍了基于服务器 log 的热门页面浏览量统计。 最后通过运行结果的验证,我们发现,从 web 服务器 log 中得到的 url,往往更多的是请求某个资源地址(/*.js、/*.css),如果要针对页面进行统计往往还需要进行过滤。而在实际电商应用中,相比每个单独页面的访问量,我们可能更加关心整个电商网站的网络流量。这个指标,除了合并之前每个页面的统计结果之外,还可以通过统计埋点日志数据中的“pv”行为来得到....

网站总浏览量(PV)的统计
衡量网站流量一个最简单的指标,就是网站的页面浏览量(Page View,PV)。用户每次打开一个页面便记录1次PV,多次打开同一页面则浏览量累计。一般来说,PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量,如同一个来访者通过不断的刷新页面,也可以制造出非常高的PV。
我们知道,用户浏览页面时,会从浏览器向网络服务器发出一个请求(Request),网络服务器接到这个请求后,会将该请求对应的一个网页(Page)发送给浏览器,从而产生了一个PV。所以我们的统计方法,可以是从web服务器的日志中去提取对应的页面访问然后统计,就向上一节中的做法一样;也可以直接从埋点日志中提取用户发来的页面请求,从而统计出总浏览量。
所以,接下来我们用UserBehavior.csv作为数据源,实现一个网站总浏览量的统计。我们可以设置滚动时间窗口,实时统计每小时内的网站PV。
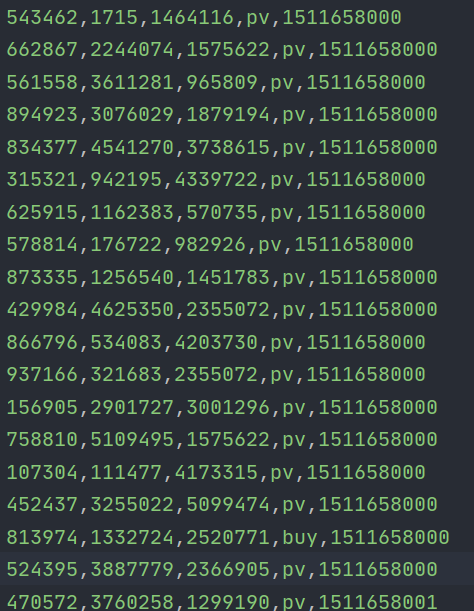
在src/main/scala下创建 PageView.scala 文件,具体代码如下:
object PageView {
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
def main(args: Array[String]): Unit = {
// 创建 流处理的 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置时间语义为 eventTime -- 事件创建的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置程序的并行度
env.setParallelism(1)
// 读取文本数据
env.readTextFile("YOUR_PATH\\UserBehavior.csv")
// 对文本数据进行封装处理
.map(data => {
val dataArray: Array[String] = data.split(",")
// 将数据封装进 UserBehavior
UserBehavior(dataArray(0).toLong,dataArray(1).toLong,dataArray(2).toInt,dataArray(3),dataArray(4).toLong)
})
// 设置水印
.assignAscendingTimestamps(_.timestamp * 1000)
// 过滤出 "pv" 数据
.filter(_.behavior == "pv")
// 求和
.map(x => ("pv",1))
.keyBy(_._1)
// 设置TimeWindow,每一小时做一次聚合
.timeWindow(Time.seconds(60 * 60))
.sum(1)
.print()
// 执行程序
env.execute("Page View Job")
}
}
程序运行的结果:
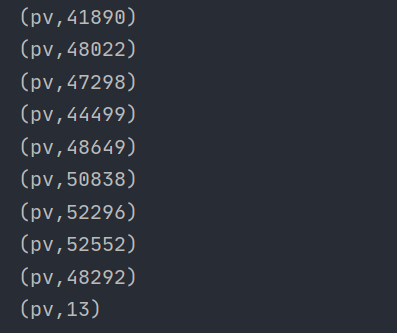
网站独立访客数(UV)的统计
在上节的例子中,我们统计的是所有用户对页面的所有浏览行为,也就是说,同一用户的浏览行为会被重复统计。而在实际应用中,我们往往还会关注,在一段时间内到底有多少不同的用户访问了网站。
另外一个统计流量的重要指标是网站的独立访客数(Unique Visitor,UV)。UV指的是一段时间(比如一小时)内访问网站的总人数,1天内同一访客的多次访问只记录为一个访客。通过IP和cookie一般是判断UV值的两种方式。当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个Cookie,通常放在这个客户端电脑的C盘当中。在这个Cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。
当然,对于UserBehavior 数据源来说,我们直接可以根据userId来区分不同的用户。
在src/main/scala下创建UniqueVisitor.scala文件,具体代码如下:
object UniqueVisitor {
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
case class UvCount(windowEnd: Long, count: Long)
def main(args: Array[String]): Unit = {
// 创建 流处理的 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置时间语义为 eventTime -- 事件创建的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置程序的并行度
env.setParallelism(1)
// 读取文本数据
env.readTextFile("YOUR_PATH\\UserBehavior.csv")
// 对文本数据进行封装处理
.map(data => {
val dataArray: Array[String] = data.split(",")
// 将数据封装进 UserBehavior
UserBehavior(dataArray(0).toLong,dataArray(1).toLong,dataArray(2).toInt,dataArray(3),dataArray(4).toLong)
})
// 设置水印
.assignAscendingTimestamps(_.timestamp * 1000)
// 过滤出 "pv" 数据
.filter(_.behavior == "pv")
// 设置窗口大小为一个小时
.timeWindowAll(Time.seconds(60 * 60))
.apply(new UvCountByWindow())
.print()
// 执行程序
env.execute("Page View Job")
}
class UvCountByWindow extends AllWindowFunction[UserBehavior,UvCount,TimeWindow]{
override def apply(window: TimeWindow, input: Iterable[UserBehavior], out: Collector[UvCount]): Unit = {
// 初始化一个Set集合,用于将存储的用户id数据进行去重
var idSet: Set[Long] = Set[Long]()
for ( userBehavior <- input){
idSet += userBehavior.userId
}
// 输出结果
out.collect(UvCount(window.getEnd,idSet.size))
}
}
}程序运行的结果:
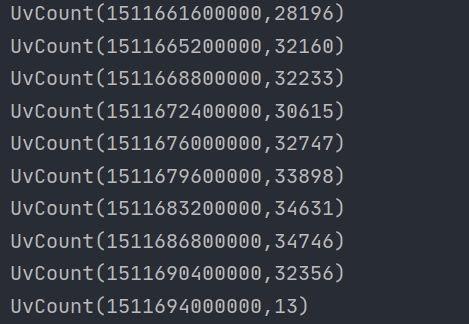
到了这一步,让我们想想,还有没有更好的方案?

使用布隆过滤器的 UV 统计
在上节的例子中,我们把所有数据的userId都存在了窗口计算的状态里,在窗口收集数据的过程中,状态会不断增大。一般情况下,只要不超出内存的承受范围,这种做法也没什么问题;但如果我们遇到的数据量很大呢?
把所有数据暂存放到内存里,显然不是一个好注意。我们会想到,可以利用redis这种内存级k-v数据库,为我们做一个缓存。但如果我们遇到的情况非常极端,数据大到惊人呢?比如上亿级的用户,要去重计算UV。
如果放到redis中,亿级的用户id(每个20字节左右的话)可能需要几G甚至几十G的空间来存储。当然放到redis中,用集群进行扩展也不是不可以,但明显代价太大了。
一个更好的想法是,其实我们不需要完整地存储用户ID的信息,只要知道他在不在就行了。所以其实我们可以进行压缩处理,用一位(bit)就可以表示一个用户的状态。这个思想的具体实现就是布隆过滤器(Bloom Filter)。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是1。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的
我们的目标就是,利用某种方法(一般是Hash函数)把每个数据,对应到一个位图的某一位上去;如果数据存在,那一位就是1,不存在则为0。
接下来我们就来具体实现一下。
注意这里我们用到了redis连接存取数据,所以需要加入redis客户端的依赖:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.1</version>
</dependency>
</dependencies>在src/main/scala下创建UniqueVisitor.scala文件,具体代码如下:
object UvWithBloomFilter {
// 定义样例类,用于封装数据
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
case class UvCount(windowEnd: Long, count: Long)
def main(args: Array[String]): Unit = {
// 创建 流处理的 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置时间语义为 eventTime -- 事件创建的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置程序的并行度
env.setParallelism(1)
// 读取文本数据
env.readTextFile("YOUR_PATH\\UserBehavior.csv")
// 对文本数据进行封装处理
.map(data => {
val dataArray: Array[String] = data.split(",")
// 将数据封装进 UserBehavior
UserBehavior(dataArray(0).toLong, dataArray(1).toLong, dataArray(2).toInt, dataArray(3), dataArray(4).toLong)
})
// 设置水印 [ 升序时间戳 ]
.assignAscendingTimestamps(_.timestamp * 1000)
// 只统计 "pv" 数据
.filter(_.behavior == "pv")
.map(data => ("dummyKey", data.userId))
.keyBy(_._1)
// 设置窗口大小为一个小时
.timeWindow(Time.hours(1))
// 我们不应该等待窗口关闭才去做 Redis 的连接 -》 数据量可能很大,窗口的内存放不下
// 所以这里使用了 触发窗口操作的API -- 触发器 trigger
.trigger(new MyTrigger())
.process(new UvCountWithBloom())
.print()
// 执行程序
env.execute("uv with bloom Job")
}
// 自定义窗口触发器
class MyTrigger() extends Trigger[(String, Long), TimeWindow] {
// 如果事件是基于 processTime 触发
override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
// 如果事件是基于 eventTime 触发
override def onEventTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
// 收尾工作
override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {}
// 每来一个元素就触发
override def onElement(element: (String, Long), timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
// 每来一条数据,就直接触发窗口操作,并清空所有窗口状态
TriggerResult.FIRE_AND_PURGE
}
}
// 定义一个布隆过滤器
class Bloom(size: Long) extends Serializable {
// 位图的总大小
private val cap = if (size > 0) size else 1 << 27
// 定义 hash 函数
def hash(value: String, seed: Int) = {
var result: Long = 0L
for (i <- 0 until value.length) {
result = result * seed + value.charAt(i)
}
result & (cap - 1)
}
}
// 自定义窗口处理函数
class UvCountWithBloom() extends ProcessWindowFunction[(String, Long), UvCount, String, TimeWindow] {
// 创建 redis 连接
lazy val jedis = new Jedis("node02", 6379)
lazy val bloom = new Bloom(1 << 29)
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[UvCount]): Unit = {
// 位图的存储方式, key 是 windowEnd,value 是 bitmap
val storeKey: String = context.window.getEnd.toString
var count = 0L
// 把每个窗口的 uv count 值也存入 redis 表,存放内容为(windowEnd > uvCount),所以要先从 redis 中读取
if (jedis.hget("count", storeKey) != null) {
count = jedis.hget("count", storeKey).toLong
}
// 用 布隆过滤器 判断当前用户是否已经存在
// 因为是每来一条数据就判断一次,所以我们就可以直接用last获取到这条数据
val userId: String = elements.last._2.toString
// 计算哈希
val offset: Long = bloom.hash(userId, 61)
// 定义一个标志位,判断 redis 位图中有没有这一位
val isExist: lang.Boolean = jedis.getbit(storeKey, offset)
if (!isExist) {
// 如果不存在,位图对应位置1,count + 1
jedis.setbit(storeKey, offset, true)
jedis.hset("count", storeKey, (count + 1).toString)
out.collect(UvCount(storeKey.toLong, count + 1))
} else {
// 输出到 flink
out.collect(UvCount(storeKey.toLong, count))
}
}
}
} 程序运行的效果如下所示:
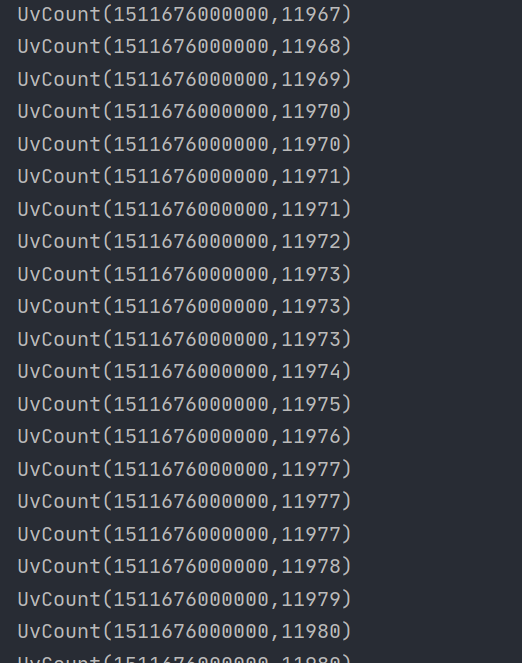
可以发现,我们改进之后的程序,不再是把所有需要统计的数据都放到本地内存里进行计算,而是来一条数据,我们就输出,然后利用布隆过滤器进行判断,并将最新的结果存入Redis。
等到程序运行完毕,我们打开 redis,输入hgetall count查看统计的最终结果,可以发现跟我们之前统计的结果是一致的。
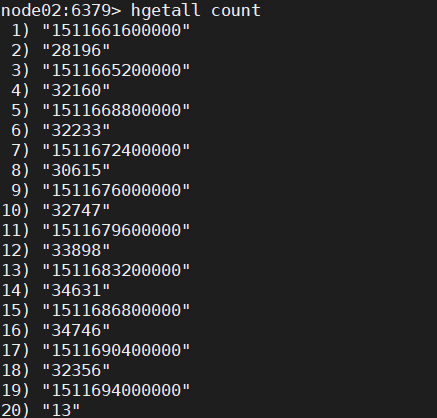
要是嫌利用 redis 的 bitmap 自己手动实现一个简单的布隆过滤器过程繁琐的话,我们也可以利用Flink官方实现的布隆过滤器来实现。具体代码见下:
/*
* @Author: Alice菌
* @Date: 2020/12/5 18:29
* @Description:
// uv: unique visitor
// 有多少用户访问过网站;pv按照userid去重
// 滑动窗口:窗口长度1小时,滑动距离5秒钟,每小时用户数量1亿
// 大数据去重的唯一解决方案:布隆过滤器
// 布隆过滤器的组成:bit数组,哈希函数
*/
object UvByBloomFilterWithoutRedis {
case class UserBehavior(userId: Long,
itemId: Long,
categoryId: Long,
behavior: String,
timestamp: Long)
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream: DataStream[String] = env.readTextFile("YOUR_PATH\\UserBehavior.csv")
.map(line => {
val arr: Array[String] = line.split(",")
UserBehavior(arr(0).toLong, arr(1).toLong, arr(2).toLong, arr(3), arr(4).toLong * 1000)
})
.filter(_.behavior.equals("pv")) // 只处理 pv 数据
.assignAscendingTimestamps(_.timestamp) // 分配升序时间戳
.map(r => ("key", r.userId)) // 对每个元素做处理
.keyBy(_._1) // 分到同一组操作
.timeWindow(Time.hours(1)) // 设置滑动窗口时间
.aggregate(new UvAggFunc, new UvProcessFunc) // 自定义预聚合
// 打印结果
stream.print()
// 执行任务
env.execute()
}
// 直接用聚合算子【count,布隆过滤器】
class UvAggFunc extends AggregateFunction[(String,Long),(Long,BloomFilter[lang.Long]),Long]{
override def createAccumulator(): (Long, BloomFilter[lang.Long]) = (0,BloomFilter.create(Funnels.longFunnel(), 100000000, 0.01))
override def add(value: (String, Long), accumulator: (Long, BloomFilter[lang.Long])): (Long, BloomFilter[lang.Long]) = {
var bloom: BloomFilter[lang.Long] = accumulator._2
var uvCount: Long = accumulator._1
// 通过布隆过滤器判断是否存在,不存在则 +1
if (!bloom.mightContain(value._2)){
bloom.put(value._2)
uvCount += 1
}
(uvCount,bloom)
}
override def getResult(accumulator: (Long, BloomFilter[lang.Long])): Long = accumulator._1 // 返回 count
override def merge(a: (Long, BloomFilter[lang.Long]), b: (Long, BloomFilter[lang.Long])): (Long, BloomFilter[lang.Long]) = ???
}
class UvProcessFunc extends ProcessWindowFunction[Long,String,String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[Long], out: Collector[String]): Unit = {
// 拿到 Windows 的开始和结束时间
val start: Timestamp = new Timestamp(context.window.getStart)
val end: Timestamp = new Timestamp(context.window.getEnd)
out.collect(s"窗口开始时间为:$start 到 $end 的 uv 为 ${elements.head}")
}
}
}
程序的运行结果:
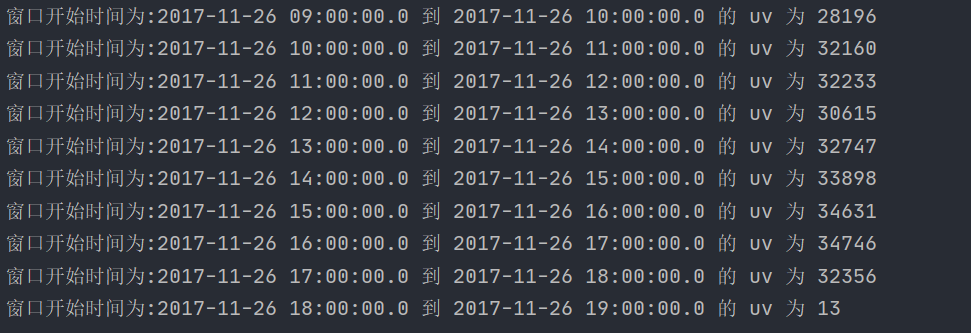
小结
本期文章,为大家讲解了在基于flink的电商用户行为数据分析的项目中,如何基于埋点日志数据实现网络流量统计的功能。一共介绍了3种不同的实现方式,其中光统计 UV 就有3种解决方案!文章中已将完整代码贴出,对代码有任何疑问的小伙伴均可加我微信私聊,交流学习!你知道的越多,你不知道的也越多,我是Alice,我们下一期见!
受益的朋友记得三连支持小菌!
文章持续更新,可以微信搜一搜「 猿人菌 」第一时间阅读,思维导图,大数据书籍,大数据高频面试题,海量一线大厂面经…期待您的关注!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1315次2023-09-05 11:03:36
-
浏览量:156次2023-08-30 15:38:33
-
浏览量:1282次2023-01-12 17:08:25
-
浏览量:3716次2022-03-20 09:01:41
-
浏览量:4860次2021-05-18 15:15:50
-
2023-01-13 11:33:00
-
浏览量:1810次2023-12-19 17:38:07
-
浏览量:3339次2024-02-28 16:15:25
-
浏览量:16889次2020-12-19 14:41:57
-
浏览量:34724次2020-12-18 00:01:24
-
浏览量:2836次2023-03-29 15:59:47
-
浏览量:5527次2021-07-30 15:32:45
-
浏览量:20207次2020-12-21 18:20:26
-
浏览量:1021次2023-01-29 11:28:01
-
浏览量:1692次2023-07-05 10:18:06
-
浏览量:5324次2021-08-02 09:33:43
-
浏览量:1225次2023-11-18 15:07:05
-
浏览量:6083次2021-04-16 15:01:12
-
浏览量:6560次2021-01-17 16:24:32
大数据梦想家
一枚有趣的程序员,更多精彩内容请移步公众号@大数据梦想家

-
8篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
大数据梦想家

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
