

教AI代理在幻想世界中交流和行动

Credit: Pixabay/CC0 Public Domain
近年来,包括自然语言处理(NLP)技术在内的人工智能(AI)工具已经变得越来越复杂,在各种任务中均取得了优异的成绩。NLP技术经过专门设计,可以理解人类语言并产生适当的响应,从而实现人类与人工代理之间的交流。
其他研究还介绍了可以自动导航虚拟或视频游戏环境的面向目标的代理。到目前为止,NLP技术和面向目标的代理通常是单独开发的,而不是组合为统一的方法。
佐治亚理工学院和Facebook AI Research的研究人员最近探索了为目标驱动的代理配备NLP功能的可能性,以便他们可以与其他角色交谈并在幻想游戏环境中完成所需的动作。他们的论文在arXiv上预先发表,表明这两种方法结合起来可取得显著成果,产生的游戏角色说话和行动的方式与其总体动机一致。
进行这项研究的研究者之一Prithviraj Ammanabrolu对TechXplore表示:“与人类和其他代理商进行沟通以实现目标的代理商仍然很原始。” “我们基于这样的假设进行操作,这是因为当前大多数NLP任务和数据集都是静态的,因此忽略了大量文献,这表明交互性和语言基础对于有效的语言学习是必要的。”
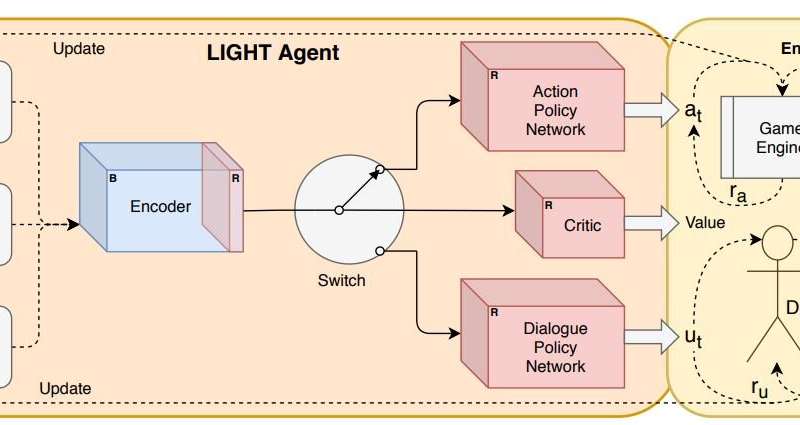
研究人员开发的神经网络架构。Credit: Ammanabrolu et al
培训AI代理的主要方法之一是让他们在交互式模拟环境中练习技能。交互式叙事游戏,也称为文本冒险游戏,对于培训目标驱动型和对话型代理人特别有用,因为它们可以进行各种与言语和动作相关的交互。
Ammanabrolu说:“交互式叙事游戏是一种模拟,在这种模拟中,代理人完全通过自然语言与世界互动-使用文本描述,命令和对话来“感知”,“作用”和“与世界对话”。“作为这项工作的一部分,FAIR的ParlAI团队创建了LIGHT,这是一款大规模的,众包的幻想文字冒险游戏,您可以在这些世界中扮演和扮演角色。这是我们进行实验的平台。”
研究人员用来训练目标驱动的对话代理的平台LIGHT,提供了大量包含各种字符,位置和对象的幻想世界。但是,平台本身并没有为在这些环境中导航的每个角色设置特定的目标。

用于训练AI代理的数据示例。Credit: Ammanabrolu et al
因此,在开始训练代理之前,Ammanabrolu和他的同事编译了一个可以分配给游戏中角色的任务数据集,他们将其称为LIGHT-Quests。这些任务是通过众包收集的,每个任务都为LIGHT中的特定角色提供了短期,中期和长期的动机。随后,团队要求人们玩游戏,并在他们尝试完成这些任务时收集了有关其玩法的演示(即,他们的角色如何行动,说话和在幻想世界中导航)。
“例如,想象一下你是一条龙,”阿玛纳布罗鲁说。“在这个平台上,您的短期动机可能是追回被盗的金蛋并惩罚做过此事的骑士,但潜在的长期动机则是为自己建立最大的宝藏。”
除了创建LIGHT-Quests数据集并收集人类如何玩游戏的演示外,Ammanabrolu和他的同事还修改了ATOMIC(一种现有的常识知识图(即,可用于训练机器的常识事实图集))以适合LIGHT中的幻想世界。研究人员设计的新的与光有关的常识性事实地图集被编译成另一个数据集,称为ATOMIC-LIGHT。

LIGHT界面的屏幕截图。Credit: Ammanabrolu et al
随后,研究人员开发了一种基于机器学习的系统,并使用称为强化学习的方法对他们创建的两个数据集(LIGHT-Quests和ATOMIC-LIGHT)进行了训练。通过这次培训,他们实质上教会了系统在LIGHT中执行与其所体现的虚拟角色的动机一致的动作,并向其他角色说出可能有助于他们完成角色任务的事物。
“运行AI代理的部分神经网络已在ATOMIC-LIGHT以及原始LIGHT和其他数据集(例如Reddit)上进行了预训练,以使人们对如何在幻想世界中行动和交谈有一个大致的认识,”说过。“输入,对世界的描述以及其他角色的对话通过预先训练的神经网络发送到交换机。”
当预训练的神经网络将输入数据发送到此开关时,该开关将决定代理是否应执行操作或对另一个角色说些什么。根据决定,它将网络重定向到两个策略网络之一,这两个策略网络分别用于确定角色应该说什么具体动作或说什么句子。
Ammanabrolu和他的同事们还放置了另一个受过训练的AI代理,该代理可以在LIGHT培训环境中行动和交谈。该第二代理在尝试完成其任务时充当主要角色的伙伴。
由两个代理完成的所有动作均由游戏引擎处理,游戏引擎还会检查以查看代理在完成任务中取得了多少进展。此外,由角色执行的所有对话均由地牢大师(DM)审查,该大师根据他们产生的语音的“自然程度”以及其对幻想世界的适应性对得分进行评分。DM本质上是在人类游戏演示中训练的另一种机器学习模型。

Credit: Ammanabrolu et al
“使用NLP中常见的静态数据集训练AI时,您看到的大多数趋势现在都不适用于交互式环境,” Ammanabrolu说。“从我们针对新颖任务的零射泛化的消融研究测试中获得的一项重要见解是,在交互式环境中进行大规模的预训练需要仔细选择预训练任务,即在为探员提供'一般'开放域先验知识和那些对下游任务更“特定”的方法,而静态方法仅需要特定于域的预训练才能有效转移,但最终效果不如交互式方法。”
研究人员进行了一系列初步评估,发现他们的AI代理能够在LIGHT游戏环境中以与角色动机一致的方式行动和交谈。总体而言,他们的发现表明,以交互方式训练与环境相关的数据的神经网络可以导致AI代理以“自然”的方式和与其动机保持一致的方式行动和交流。
Ammanabrolu及其同事的工作提出了一些有关预训练神经网络以及将NLP与RL结合的潜力的有趣问题。他们开发的方法最终可以为创建具有高级沟通技巧的高性能,目标驱动的代理铺平道路。
“ RL是解决面向目标的问题的非常自然的方法,但是从历史上来看,尝试将其与NLP的先进技术(例如BERT或GPT之类的变压器)相结合的工作相对较少,” Ammanabrolu说。“这将是我个人感兴趣的下一步工作,以了解如何更好地混合这些内容,以便更有效地为AI代理提供更好的常识性先验,使其在这些互动世界中行动和交谈。”
来源:Tech Xplore
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2704次2018-07-13 20:08:12
-
浏览量:1499次2018-07-12 09:40:46
-
浏览量:1283次2023-03-15 10:12:02
-
浏览量:2094次2020-07-28 20:16:56
-
浏览量:8370次2020-12-14 16:47:50
-
浏览量:2292次2020-07-30 18:04:03
-
浏览量:1249次2023-02-11 08:54:30
-
浏览量:1488次2018-04-28 22:12:57
-
浏览量:3341次2018-09-30 16:21:05
-
浏览量:2235次2019-01-29 21:11:04
-
浏览量:1822次2022-09-30 15:13:05
-
浏览量:3101次2019-10-16 14:42:48
-
浏览量:1824次2018-11-13 22:02:16
-
浏览量:1848次2019-04-26 11:42:22
-
浏览量:1727次2019-07-04 14:56:01
-
浏览量:2883次2020-12-02 15:29:48
-
浏览量:2740次2019-11-21 08:59:29
-
浏览量:3761次2019-02-13 22:04:58
-
浏览量:1031次2023-01-12 17:13:47

易百纳技术社区
暂无个性签名~













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
易百纳技术社区

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
