

SK海力士数据科学组织的过去、现在和未来
2017年,SK海力士成为韩国第一家成立数据科学(Data Science,简称DS)组织的制造业企业。它起始于原本分散在公司各处的40名数据分析师,如今已成为负责全公司的数据科学(DS)和人工智能(Artificial Intelligence, 简称 AI)的业务机构。该机构通过应用统计学、机器学习(Machine Learning)1和深度学习(Deep Learning)2算法 3来执行各种课题,如缺陷检测和预测、原因分析和产量分析。
半导体产业:数据科学领域充满新机遇

过去,数据分析师的主要工作是通过统计咨询来协助决策,而目前则专注于开发能够通过人工智能和大数据技术自主预测和决策的算法。
包括谷歌(Google)、脸书(Facebook)和亚马逊(Amazon)在内的全球IT公司已经建立了自己的数据科学机构,正在开发能够优化搜索、推荐、广告等的人工智能算法。与本身拥有在线平台来收集和处理数据的IT公司不同,基于生产设施的制造业企业需要在开发算法之前确保所需数据,并实现“数字化转型(Digital Transformation)”以升级优化IT系统。
通常,半导体企业较早就开始重视数据分析,因此情况比其他制造业企业要好。多年来,半导体企业持续收集了大量精准的数据,业内工程师在分析故障原因时正充分利用了这些数据。举例来说,把关于设备状态的传感器信号数据和处理后的晶圆测试数据传送到计算机服务器,工程师则利用这些积累的数据来检查设备状态和处理结果,以便采取适当的措施。
因此,半导体行业有很多机会应用最新人工智能技术,同时从设备、工艺和工程师活动数据中发现新的价值,而非从客户活动数据中发现。
SK海力士数据科学组织的足迹:“在业内(or 领域中)扎根人工智能技术”
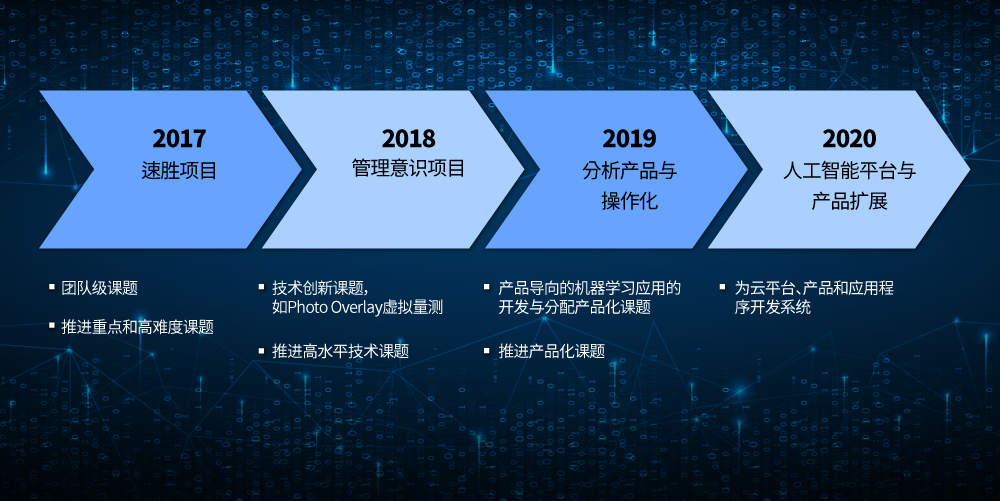
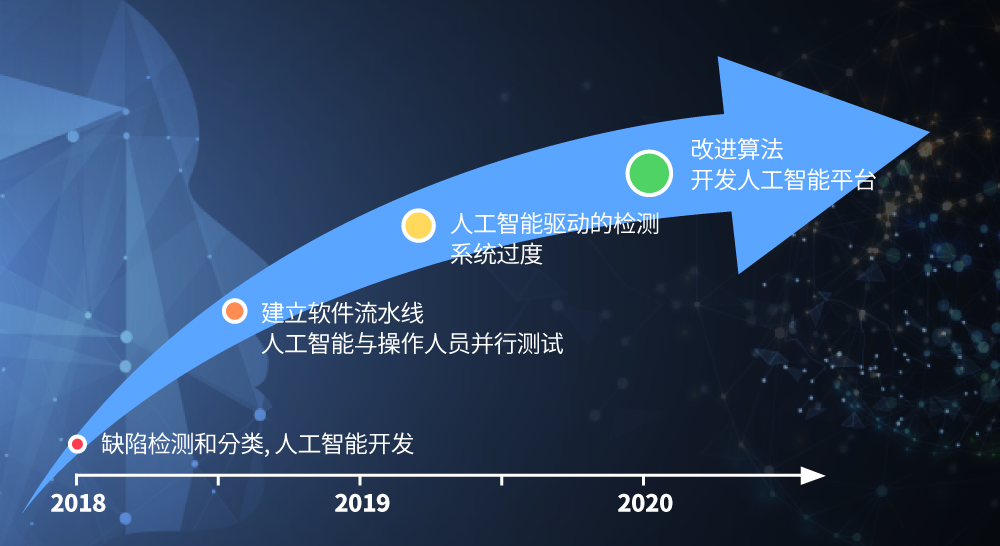
SK海力士的数据科学机构一直在该领域执行各种课题,以掌握半导体相关的专业知识,确保人工智能技术应用的经验。在上市之初,它通过应用人工智能和大数据等最新信息和通信技术(ICT)完成了速胜的课题,同时扩大了全公司的分析基础。随后,选择有助于提高产量、生产效率和质量的技术创新课题,与业内共同确定目标并展开了合作。
从2019年起,不断寻求以产品为导向的开发方法,通过收集来自业内的反馈来实现必要的功能。而且还专注于开发和分配算法,以便将分析功能用于生产线,从而构建一个解决运营问题的系统。其中,产品导向的开发工作包括一个基于图像的缺陷检测和分类课题——智能视觉检测分析4(Intelligent Visual Inspection Analytics,IVIA),以及一个根据晶圆测试结果预测芯片质量分数的课题——Sherlock5)。
此外,该部门正在努力解决不同项目为相同目的开发课题或重叠建立类似的IT基础设施的问题,以优化产品开发过程。为此,目前正在开发提供通用数据分析服务的分析平台“Design Analytics Yourself(DAY)6”以及用于运营人工智能模型的“人工智能服务平台(AI Service Platform,AIP)”。这些人工智能平台为数据分析专家提供一个能够只专注于分析工作,而不必担心人工智能模型运营的综合分析开发环境。这不仅可以最大限度地提高人工智能课题的工作效率,而且还可以有效地管理资源。
内部和外部人才共同运作的数据科学机构
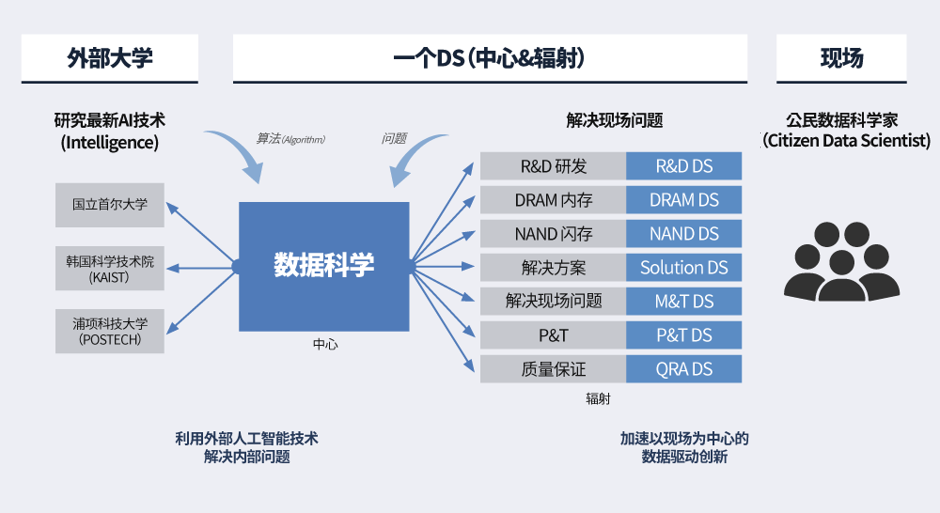
数据科学机构由总部团队和业内团队组成。域内的数据科学团队响应业内的分析要求,公司旗下的数据科学团队负责解决域内的数据科学团队无法解决的问题,并负责产品分析和平台搭建工作。
通过携手资深的数据分析专家(业内也称为公民数据科学家Citizen Data Scientist,简称CDS),域内数据科学团队在传播业内导向、基于数据的决策文化方面也发挥着重要作用。本着“课题能够在业内定义明确”的理念,SK海力士自2019年开始为业内工程师提供数据科学培训,培养他们成为兼具数据科学能力的复合型人才。一个具有分析能力的公民数据科学家(CDS)也是一个了解AI算法的价值和操作方法的专家,SK海力士预计今年培养约300名公民数据科学家(CDS)。
每年有成千上万篇关于人工智能的论文不断涌现7,公司、大学和科研机构都在不断开发新的人工智能技术。随着人工智能相关创新的迅速发展,数据科学机构与各大学建立了研究人工智能和技术应用的“人工智能协作中心(AI Collaboration Center,简称AICC),用于人工智能研究和技术应用,以利用人工智能相关的创新技术。AICC的主要目标在于探索最新人工智能技术、了解技术路线图和发展趋势、以新的视角解决业内问题、通过执行课题获得一批熟悉半导体数据的人工智能研究人员。
今年,与韩国科学技术院(KAIST)建立AICC,开展了确保AI模型运营技术的六项AI合作课题8。明年计划将合作对象扩大到国立首尔大学和浦项科技大学(POSTECH),执行22项课题。
数据科学机构目前的工作:“执行领域分析和技术创新课题”
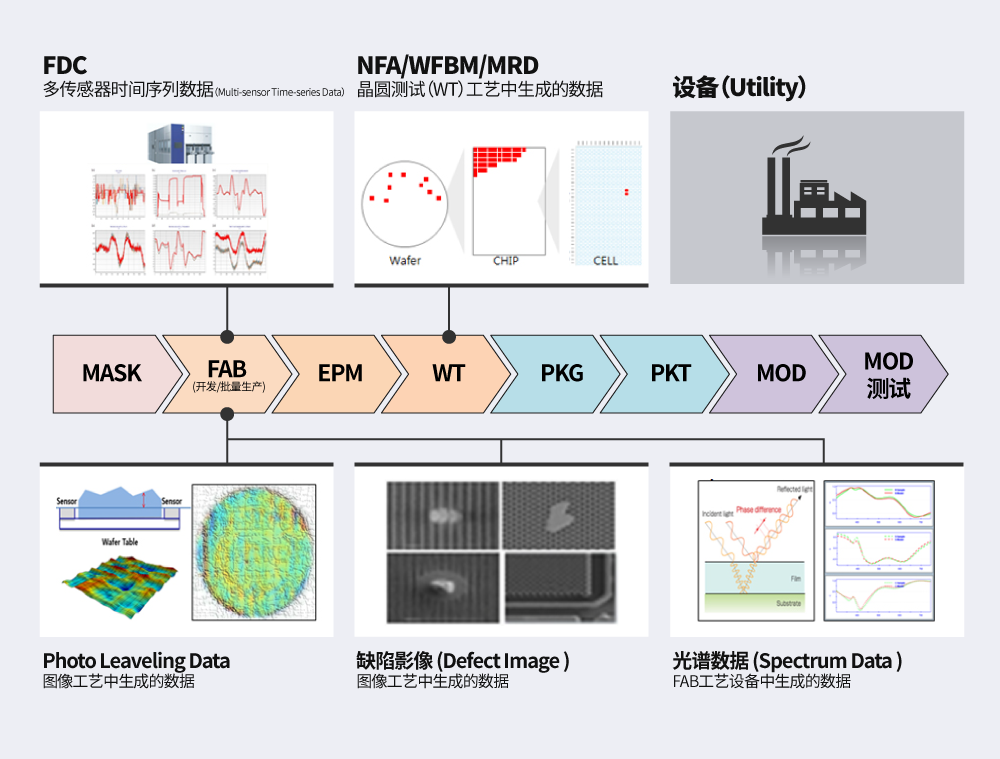
SK海力士拥有的数据在数据数量(Volume)、处理速度(Velocity)和多样性(Variety)方面都非常有意义。公司载有从半导体工艺中收集的数十PB字节(Petabyte)9的大数据(Volume),并对其进行实时处理(Velocity),以便进行缺陷检测和通知。此外,还收集和分析来自不同工艺和设备的各种数据,包括每道工序的晶圆测试数据、安装在设备上的传感器时序数据、晶圆测试数据、光电设备的晶圆高度数据、检测设备的缺陷图像数据等(Variety)。

基于这些数据,数据科学机构正在开展△设备异常检测与控制、△晶圆与内存缺陷分类、△半导体设计优化、△设备先进化等多项分析工作。此外,还开展△“设备数据分析”优化设备运行和降低能源成本;△“新闻文本分析”预测内存市场需求;△查找缺陷报告并推荐相关文件;△基于聊天机器人(Chatbot)的分析查询和可视化,以及 “群组分析(Cohort Analysis)10” 对工作环境中的重大问题进行抢占式管理。
今年以来,全公司和7个领域的数据科学团队正在推进300多个项目,包括技术创新课题的实施以及内部产品和平台的开发。这不仅包括响应每个领域要求的任务, 如设计、要素、流程、产量和设备方面,还包括整个供应链的营销、采购、人力资源管理、战略、设备和安全、健康与环境(SHE)管理。
SK海力士梦想成为基于人工智能的“智能公司”
数据科学机构的最终目标是将SK海力士发展成为基于人工智能的“智能公司”。为了实现这一目标,有必要将人工智能应用于业内生产线,并建立一个业内工程师能够自行操作的系统。为此,数据科学机构在实践过程中积累了应用人工智能课题的经验。
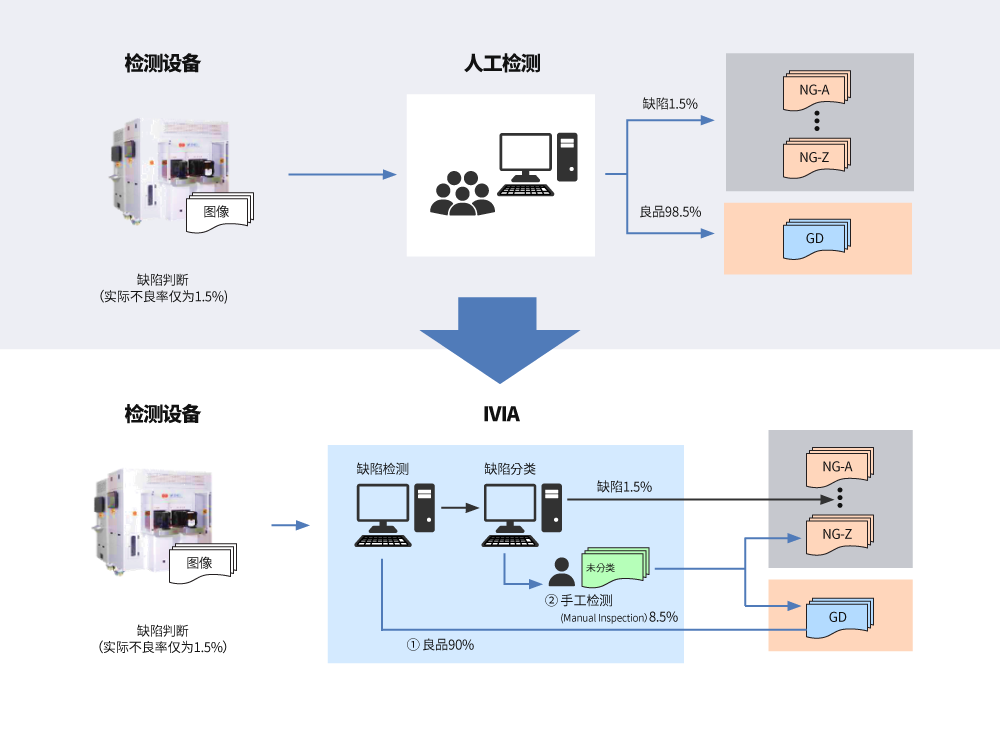
其中,最具代表性的案例——IVIA为自2018年起开展了两年的视觉缺陷检测自动化课题。通过这项课题,公司开发出用于早期检测缺陷和分类的人工智能模型,并实现了最小化可行性产品(Minimum Viable Product,简称MVP)11。同时,完成了在生产过程中由人工智能主导的检测系统。基于深度学习的缺陷检测与分类算法技术将现有的重复性人工劳动减少了90%以上,缺陷检测的准确性也进一步得到了提升。
目前,制造业使用人工智能的案例屡见不鲜,但基于人工智能建立运营系统的案例为数不多。为了转型到由人工智能主导的检测系统,应装备一个在性能下降时快速分析原因并自行恢复的AI性能监测系统。为此,人工智能模型需具备自我调试(Debugging)12功能,并在新的缺陷出现时自动学习。此外,还应建立人工智能模型的分配系统。
数据科学机构的未来发展方向
一位斯坦福大学的AI科学家Andrew Ng说过,“如果一个普通人能用不到一秒的时间做出判断的脑力工作(比如缺陷检测和分类),那我们就可以用人工智能来自动化它,无论是现在还是不久的将来。”而且他指出AI将应用于所有行业,就像过去发明电力一样带来创新。将这一创新引入并应用于SK海力士是数据科学机构一直在做也是继续要做的核心课题。
目前,数据科学机构正致力于通过△挖掘和执行业内分析课题、△加强业内分析能力以及△支持开发分析自动化工具等,在SK海力士建立基于数据的决策文化。此外,该部门正在建立由人工智能做出决策、人类管理人工智能的系统,以促进发展成为智能公司。
同时,也在不断研究和开发应业内应用的人工智能技术。目前正在引进和应用Vision13和自然语言处理(Natural Language Processing,NLP)14等成熟的人工智能技术,搭建分析开发环境和人工智能模型运营平台,提高人工智能模型的开发工作效率。
随着未来人工智能的应用范围持续扩大,业内的工作人员的角色和职责将会不同于以往。因此,要将人工智能技术应用到业内并继续加以利用,不仅要考虑与现有系统的集成,而且要考虑工作方式的创新。此外,还需要考虑关于操作人工智能模型的培训和模型管理方法,以便在人工智能出现问题时,能够在现场自行解决问题。
1允许人工智能自行学习数据并进行预测的技术或系统(程序)。
2机器学习的一个领域,以向量或图形等计算机可以处理的形式表达大数据,并建立学习这些数据的抽象模型的技术或系统(程序)。
3为解决问题而定义的一组规则和过程。
4对从测量设备出来的图像判断良品或缺陷并确定缺陷类型的课题。
5根据晶圆芯片单元测试结果,预测当组装成存储模块时的质量的课题。
6以容器(Container)方法为分析算法的开发人员提供所需开发环境的平台,它包括以下功能:Jupyter Notebook等分析代码编辑器、公司内部分析算法库、用于定期执行的工作流设计和执行、结果可视化工具。
7软件政策研究所(SPRi)(2020年)的SPRi AI简报。
8应用人工智能后的数据漂移(Drift)检测;新缺陷检测和重新分类(开集识别Open-Set Recognition、多任务学习Multi Task Learning);用有限的数据量进行学习(小样本学习,Few Shot Learning)。
9表示数据大小的单位,1PB=1024TB。
10比较和分析按每种标准分类的群组数据的分析技术。
11接收客户反馈来实现最小功能的产品;亦指响应对附加功能的要求来提高完成度的渐进式开发方法。
12查找和更正计算机程序的工作。
13通过特定算法实现人类视觉系统的技术。
14通过特定算法分析和处理人类自然语言的技术。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5149次2020-11-30 09:50:53
-
浏览量:1831次2019-07-10 14:07:41
-
浏览量:1243次2023-02-02 10:55:28
-
2020-12-01 11:13:10
-
浏览量:1797次2022-11-10 11:02:37
-
浏览量:2938次2020-11-19 09:41:02
-
浏览量:4689次2020-10-29 10:22:40
-
浏览量:3381次2020-10-20 16:43:27
-
浏览量:3326次2020-11-13 10:30:18
-
浏览量:4268次2020-11-20 10:09:29
-
浏览量:2641次2019-07-15 10:29:52
-
浏览量:3240次2020-12-04 10:41:46
-
浏览量:2928次2020-10-31 09:45:21
-
浏览量:5162次2021-02-26 17:38:02
-
浏览量:2314次2019-06-20 11:34:53
-
浏览量:1696次2020-04-21 11:32:45
-
浏览量:6543次2022-02-16 09:00:51
-
浏览量:3750次2019-07-12 13:53:57
-
浏览量:3190次2020-09-15 11:13:11

易百纳技术社区
暂无个性签名~













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
易百纳技术社区

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
