

华为达芬奇架构NPU为什么聪明?
华为达芬奇( HUAWEI DaVinci )架构,是华为自研的面向AI计算特征的全新计算架构,具备高算力、高能效、灵活可裁剪的特性,是实现万物智能的重要基础。

AI计算的核心是矩阵乘法运算,计算时由左矩阵的一行和右矩阵的一列相乘,每个元素相乘之后的和输出到结果矩阵。在此计算过程中,标量( Scalar)、向量( Vector)、矩阵(Matrix)算力密度依次增加,对硬件的AI运算能力不断提出更高要求。
华为达芬奇架构采用3D Cube针对矩阵运算做加速,大幅提升单位面积下的AI算力,每个AI Core可以在一个时钟周期内实现4096个半精度MAC操作,相比传统的CPU和GPU实现数量级的提升。为提升AI计算的完备性和不同场景的计算效率,达芬奇架构还集成了向量、标量、硬件加速器等多种计算单元。同时支持多种精度计算,支撑训练和推理两种场景的数据精度要求,实现AI的全场景需求覆盖。
华为达芬奇架构具备灵活可裁剪的特性,可用于小到几十毫瓦,大到几百瓦的训练场景,支持AI从端侧、边缘侧到中心侧的全场景部署。
华为达芬奇架构具备灵活可裁剪的特性,可用于小到几十毫瓦,大到几百瓦的训练场景,支持AI从端侧、边缘侧到中心侧的全场景部署。
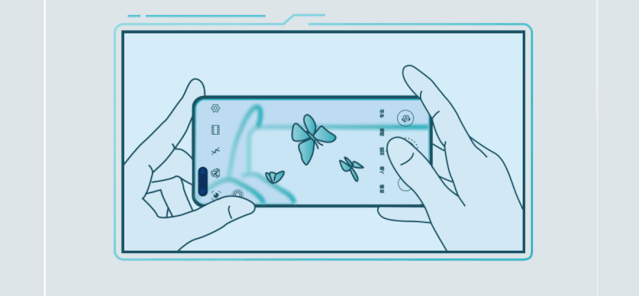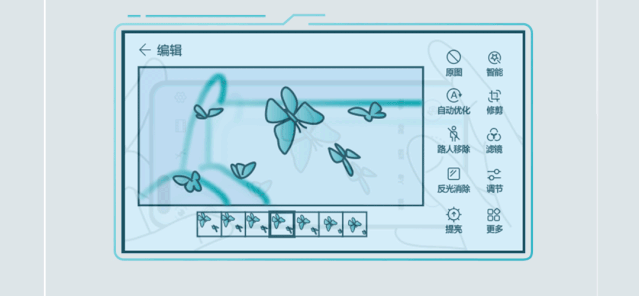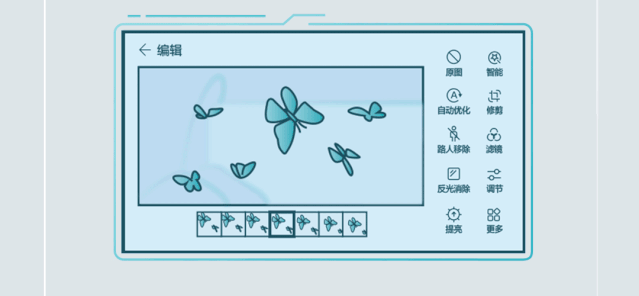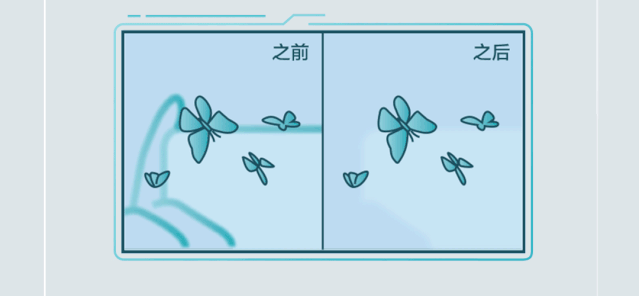
举例来说,在智能手机这一典型的AI场景中, 麒麟990 5G采用华为达芬奇架构NPU,创新设计NPU双大核加NPU微核架构,NPU大核展现卓越性能与能效,微核实现超低功耗。基于麒麟990 5G的AI强劲算力,华为P40系列带来AI路人移除、AI反光消除等功能,让更多受限于功耗和算力的AI应用成为现实。
在边缘侧、中心侧甚至是云端,华为达芬奇架构同样能够提供强在边缘侧、中心侧甚至是云端,华为达芬奇架构同样能够提供强劲算力,赋能异腾系列人工智能芯片开启智慧未来。其中,舁腾310是华为首款全栈全场景人工智能芯片,为智慧城市、自动驾驶、云业务和IT智能、智能制造、机器人等应用场景提供解决方案;异腾910更是业界算力最强的AI处理器,支持云边端全栈全场景应用,算力完全达到设计规格,充分展现强劲AI实力。
关于华为自研的达芬奇NPU架构,您怎么看?
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5997次2021-03-18 14:19:22
-
浏览量:2029次2018-09-24 21:32:55
-
浏览量:2338次2019-06-21 13:43:21
-
浏览量:1424次2018-12-19 10:33:13
-
浏览量:1650次2018-12-19 10:00:56
-
浏览量:2250次2020-02-26 19:51:32
-
浏览量:778次2024-02-28 15:53:55
-
浏览量:4229次2021-03-01 13:58:00
-
浏览量:5277次2021-09-30 18:45:43
-
浏览量:2282次2018-07-16 22:54:14
-
浏览量:2148次2018-10-12 13:30:25
-
浏览量:2014次2022-11-17 15:30:20
-
浏览量:1396次2022-12-14 13:44:12
-
浏览量:1462次2019-12-27 09:47:19
-
浏览量:1957次2018-10-18 14:34:03
-
浏览量:2621次2020-04-17 11:05:50
-
浏览量:3094次2020-11-25 10:03:26
-
浏览量:2310次2018-09-25 19:01:04
-
浏览量:1145次2023-06-06 16:15:15













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

易百纳技术社区

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
