

“人机自然交互技术”的趋势与挑战
最近AI寒冬论再起,从图像到语音再到自动驾驶这三个人工智能赛道轮番被诟病,特别是语音赛道,如今更是备受美元资本市场冷落。为什么会出现这个情况呢?我想主要还是大家当前的认知和信心问题,因为从实际商业化进程来看,图像和语音是人工智能领域早就规模商业化的领域,图像主要是面向安防等行业的专业应用,而语音主要是以智能音箱为代表的面向消费电子的个人应用,其他比如金融、医疗、零售、客服等AI应用相对规模还是小一些,而自动驾驶更是需要时间,短期内商业普及的可能性微乎其微。从最近五年的融资事例来看,人工智能的融资总额还在上升,但是已经越来越集中于A轮以后的企业,也就是说资本更加看较为成熟的AI公司。最近AI寒冬论再起,从图像到语音再到自动驾驶这三个人工智能赛道轮番被诟病,特别是语音赛道,如今更是备受美元资本市场冷落。为什么会出现这个情况呢?我想主要还是大家当前的认知和信心问题,因为从实际商业化进程来看,图像和语音是人工智能领域早就规模商业化的领域,图像主要是面向安防等行业的专业应用,而语音主要是以智能音箱为代表的面向消费电子的个人应用,其他比如金融、医疗、零售、客服等AI应用相对规模还是小一些,而自动驾驶更是需要时间,短期内商业普及的可能性微乎其微。从最近五年的融资事例来看,人工智能的融资总额还在上升,但是已经越来越集中于A轮以后的企业,也就是说资本更加看较为成熟的AI公司。
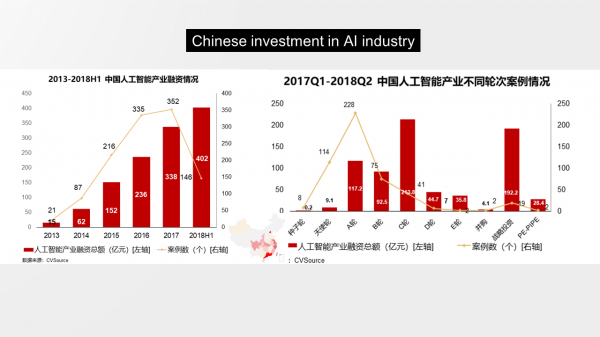
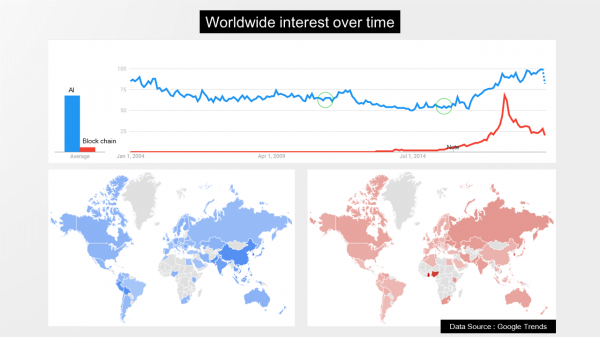
事实上,商业化进程更快的技术率先遇到信心低谷也是正常现象,毕竟技术和市场都存在一定的交叉周期,过早落地就意味着暴露出更多实际应用的问题,这就需要资本低谷来消化技术爆发早期的泡沫,这总比一些技术或者产品的“见光死”要好很多。早期互联网和移动互联网也都经历了类似的阶段,智能手机的孕育期也超过了十年并且更迭了一波巨头才实现爆发前夜的积累,似乎有点符合股票市场的艾略特波浪理论。不过语音相对更加凄惨一些,基础技术的研究差不多有60多年的历史,直到最近几年才有像样一点的产业落地,而且语音相对图像天生就没有夺目的本领,语音赛道的低调让人觉得没有图像赛道那样炫目多彩。这一点其实就很不符合美元基金的审美逻辑,美元基金强调的是故事的性感,而且更加希望公司能够登陆美股市场。当然,换个角度来看,语音赛道并非一个烧钱的赛道,事实上烧钱的业务本身也有问题,技术的优势在于先发优势,只有唯快不破才能立于不败之地,而资本只是帮助构建壁垒的工具。这个世界有太多事情并不是烧钱就能获得的,正确往往就是不容易。比如人工智能和区块链,虽然区块链的技术理念很好,但是太过于炒作并且只为牟利不顾道德,所以从全球关注趋势来看,可以借用一句俗语“We know more than we can tell”来总结。
进一步的说,声音虽然承载了人类的思想和情感,但是图像却承载了人类的表象和直觉,显然人类的第一印象,内涵丰富远远比不上外表艳丽,这是人类基于生殖繁衍的本性追求,也是无可厚非。更让人恼火的是,声音天然还不具有群体示范效应,比如在人数众多的会场,演示图像总是容易引起观众的惊叹,而若是演示语音则一般都会是灾难,对观众(所以不叫听众)来说,“看”总比“听”更容易High起来。何况我们人类也没很好解决聚众场所的“鸡尾酒会效应”问题,这种场合下的智能语音体验绝对是一塌糊涂。即便相对简单的家居环境,做好远场技术也是难度极大的挑战。到现在为止,我们也没有很好解决远场通话和远场识别问题,这点大家可以从全球销量累积已经过亿台的智能音箱产品中得到验证,可以肯定的是,智能音箱已经应用了最为先进的技术,但是仍然远远达不到很多AI厂商所给大家描绘或者演示的体验预期,事实上,短期内也不可能达到。
上面提到了“远场”这一概念,这是借鉴的学术名词,一般我们定义为1尺以上的距离,1尺大概是1KHZ单频声波的一个波长,也是一个手臂自由操控的距离,为什么要定义这一概念?主要是为了让行业对新技术有一个新的认知,远场语音交互技术主要是解决真实场景下舒适距离内人机任务对话和服务的问题,舒适距离的意思就是不要太远也不要太近,太远就会让人不自觉提高说话声音,这增加了能耗容易让人疲劳,太近了则会触发人类的安全意识,天天趴在耳朵上说话也受不了。为了更加准确定义场景,我们一般取5米作为标尺,事实上3米之内才是最好的距离。所以,远场这个概念就是希望加强人们对于语音可以释放双手这一最大魅力特性的认知,远场就是语音新技术最为显著的标签,这也是声智对语音技术做出的主要贡献之一。
但是,即便以远场语音交互技术为核心的智能音箱全球爆发,国内更是在推出后一年时间就达到了2200万台的销量,仍然还是面临了很多质疑和批评。这些质疑主要集中在两点:一是语音赛道的商业趋势问题,二是应对巨头竞争的策略问题。实际上这两个问题有些相悖,第二个问题已经例证了第一个问题的尴尬,就是因为这个赛道太重要了,所以全球巨头都在其中竞争,包括了这个时代最有钱的所有互联网巨头:亚马逊、谷歌、微软、苹果、脸书、三星、百度、阿里、腾讯、华为、小米等等。
即便如此,第一个问题我们还要阐述清晰,因为这不仅有市场趋势问题,还有商业路径问题。我们首先看下面一张图片,我们知道全球最大的图书馆是美国国会图书馆,大概有3000多万本藏书,若每本书按照100万字来统计,总共也就30TB左右的数字容量,实际上人类每年产生的文字资料总共也就160TB。相比之下,仅Facebook一家产生的数据就有300 x 365 TB,全球的数据可能超过了2000PB,而且这个总量还在快速增加。那么面对这些海量的数据,我们人类怎么才能获取知识?我们一生也不可能读完美国国会图书馆的藏书,就更没有可能遍历当今的机器数据。当然我们知道这其中很多都是重复数据,但是筛选重复信息本身也是人类学习的过程。显然,我们人类无法记住1亿人的面孔,也无法辨识1亿人的声音。人类知识和机器知识实际上已经开始各成体系,机器显然具有比人类更强的知识去重、筛选、复制和迭代的能力,而我们人类知识想要获得更快的发展,也必须依赖机器知识的支撑,这就必须要解决人类知识和机器知识的交互相通问题,怎么才能简单的把机器所理解的知识复制粘贴到人类世界?以前文本时代我们有搜索引擎,那以语音图像为主的人工智能时代呢?所以,我们必须要有人机自然交互系统,只有这样才能高效的获取更有价值的机器知识,才能解决未来数据爆炸时代的知识获取问题。至于商业化路径,其实搜索引擎已经做了很好的示范,人机交互系统肯定会催生更多的商业变现路径。

至于第二点对于巨头加入竞争的担忧,其实任何一个赛道只要未来市场空间足够大,就必然会产生这种结果。巨头为了支撑不断攀升的市值,就必须布局未来天花板足够高的产业,即便这个产业的商业模式当前还比较模糊,除非这个行业没有足够的商业空间或者战略价值
。我们一定要相信这个世界的聪明人很多,即便倒下了很多巨头,也从来没有哪个巨头纯粹是因为战略方向问题倒下的,更多的原因反而是巨头在执行方面出现了巨大的问题,战略其实也是一个执行问题。
但是我们也要承认语音行业的不足,语音行业还比较缺乏对于商业落地的认知,若比较图像、语音和自动驾驶这三个赛道,语音特别喜欢使用晦涩的术语比如自动语音识别、自然语言理解等等来给技术贴标签,而不像人脸识别、车牌识别、自动驾驶这样直接对应场景应用。而更为麻烦的是,晦涩的术语不仅增加了商务对于场景的解释难度,也拔高了客户对于技术的应用预期。这其实都非常不利于新技术在商业的规模化应用。
举个例子,“人机自然交互技术”就倒霉在这个术语上,这估计是人类追求的终极梦想,可以作为学术术语,但是落地到产业这个名词就过于抬高预期,非常不友好。坦诚的来说,我们现在能做好人机任务对话特别是远场系统就相当厉害了,至于能否挑战人类智慧现在还是看不到任何苗头。即便作为学术名称,却也感觉有点单薄,不如学学通信领域用“G”来定义。这完全可以类比,因为通信解决的是人和人交互的问题,人机自然交互解决的是人和机器交互的问题。随着机器的数量越来越多而且越来越智能,人和机器的交互将是未来世界的主要问题。若采用“G”来划分人机交互技术,则大概可以划分成如下5代,和移动通信类似,当前也就在第4代阶段,距离5G还有一定的周期。
即便参照“G”的分类方法也有很多种,若以商业普及作为重要的参考因素,个人觉得可以按照如下的方式来划分:
第1代人机交互技术:
以旋钮和键盘为代表,以模拟信号和字符为主要交互手段,可交互信息复杂度较高,效率很低,只能实现相对简单的任务,但是可靠性也最强。这个阶段的产品主要是包括打字机、电视、照相机、早期计算机、功能手机等各种电子设备,一般都是小巧简单的操作系统或者不用操作系统。
第2代人机交互技术:
以鼠标为代表,以复杂图形为主要交互手段,可交互信息复杂度较低,效率得到提升,易用性增强,学习成本降低。这个阶段的产品主要就是个人计算机,Windows和Linux是代表性的操作系统。
第3代人机交互技术:
以触摸屏为代表,以简单图形为主要交互手段,可交互信息复杂度更低,易用性提升,学习成本急剧降低。这个阶段的产品主要就是以触摸屏为核心的智能手机,IOS和Android是代表性的操作系统。
第4代人机交互技术:
以语音为代表,以远场语音为主要交互手段,从这个阶段开始,人机交互的作用半径变得更远,真正释放了双手,而且人机交互变得更加简单,同时人机交互和内容服务耦合更强,交互具备了知识学习和传递的属性,但是由于存在更多模糊空间,远场语音交互的可靠性相对下降。Amazon Alexa、Baidu DuerOS、iFlytek iFlyOS和SoundAI Azero是代表性的交互系统。
第5代人机交互技术:
以多传感融合为主要交互手段,可交互信息的理解度和可靠性更高,融合交互将成为人和机器互相学习的关键路径,并且这个阶段人机交互的智能程度和主动程度都会得到大幅提升,机器可以感知人类的情感并且与人发起主动交互。
再总结探讨一下,第5代人机交互(5G or 5I? 5I means the fifth generationhuman-robot interaction technology)的技术趋势可以暂时归结为下面4个方向:
第1个方向就是远场化,虽然第4代人机交互就主打远场语音交互,但是我们要坦诚地面对现实的残酷,当前的技术远没有那么好,我们在远场可靠性方面还有很多难点没有突破,比如多轮交互、多人噪杂等场景还有待突破,还有需求较为迫切的人声分离等技术。第5代技术应该彻底解决这些问题,让机器听觉远超人类的感知能力。这不能仅仅只是算法的进步,需要整个产业链的共同技术升级,包括更为先进的传感器和算力更强的芯片。更为重要的则是基础理论技术的进步,特别是声学的基础理论突破,我们已经等待太久了。当然这也很难,比如生理声学就受制于当前实验条件和人类伦理的约束比较难于突破,所以脑机接口当前来看就更加困难,直接挑战人类智慧的技术路线当前来看都不太靠谱。
第2个方向就是融合化,“声光电热力磁”这些物理传感手段,必然都要融合在一起,只有这样机器才能感知世界的真实信息,这是机器能够学习人类知识的前提条件。而且,机器必然要超越人类的五官,能够看到人类看不到的世界,听到人类听不到的世界。机器的感知能力必须要超越人类,事实上众多仪器也已经达到了这个目标,只不过,我们要把这些先进的传感手段做的更加小巧更加便宜更加可靠,这是高端技术能够走进寻常百姓家的关键所在。从当前的技术进展来看,声音和图像的融合更为成熟,关键就在远场化。图像识别若应用到消费场景也必须远场化才行,比如说:抬眼一撇,从此便记住了她的容貌,而不是尴尬的站在摄像头面前不知所措,这种交互体验非常不友好更不吸引人。
第3个方向就是智能化,这也是最难实现的,因为智能本身的定义就是模糊的,这个智能化也不是类人智能,而是人类知识和机器知识互相传递的泛化,也就是让机器可以理解人类的模糊知识,这并不是自然语义处理所能解决的事情。比如“像鱼忘掉海的味道”,当前再好的NLP引擎也无法释义,同样机器也无法准确理解“小桥流水人家”,这就是意境。人也是这样,高学历也并不意味着有文化,比如我们AI公司,学历都很高但是有时就比较缺文化。机器要智能就要有文化,那怎么来实现呢?人类怎么做的呢?比如高考时候的语文和英文考试,想拿高分阅读量就是一个硬指标,所以机器也要这样,先不用管什么方法什么模型的,记忆的足够多就会有显著效果。数据足够多的公司,未来必然也会比较聪明。
第4个方向就是主动化,主动化要在智能化的基础上实现,让机器尝试理解人类情感表达。这才是人工智能最大的商业价值所在,因为人和人之间的交互过程中,特别是在有商业价值的地方,主动交互占据相当大的比例。想想其中的奥妙,当前互联网最为火热的三大领域:搜索、电商和社交,归根结底,到底是在做什么呢?搜索的商业变现为什么最终落在广告业务呢?社交的商业变现为什么最终落在游戏业务呢?若想挖掘人机交互的商业价值,主动交互就是关键的技术。只需要部分理解人类思想和情感,就能稍稍影响人类的决策,这就是巨大的商业空间。况且,机器没有人类的那么多情感负担,比如说机器怎么说甜言蜜语都不会觉得恶心,我们人类肯定不会把机器看成我们的上下级关系,也不会把人类的框框强加于机器,当然另外一个可能也是极为可怕,机器可能也无底线的无耻,其目的就是为了推销一款商品。任何技术其实都有两面性,但是掌握技术的是人类,是每一家的企业,所以一家的企业价值观决定了技术是服务人类还是败坏世界规则。归根结底,还是人的问题,人的问题,也都是教育的问题。要让机器不断学习更好的造福人类,人类也应该不断学习适应机器才是。
这点还要稍微展开一下,人世间最难的莫过于重塑一个人的思想,以远场语音为核心的人机交互技术逐渐影响人类的决策,想想这就是令人激动的伟大事业。显然,机器以海量的数据、强大的算力和优异的算法为基础,永不疲惫的进化迭代,迟早是能够大概理解一下人类的,这就足以影响一个人简单的决策了,我们人类其实也蛮懒的,日常小的决策非常依赖于周边人群的建议,这就是一种趋同性,而机器恰恰擅长参与并引导这种趋同性。当然,若将这种能力用错了地方,对人类的伤害也很大,所以搜索引擎的谷歌才会有“不作恶”这个价值观,若没有这个风险谁会闲来无事提这个价值观呢。
另外一点就是人机自然交互可能会改变人类学习知识的过程,我们已经习惯了在学校里集中学习知识的系统过程,但是随着智能手机的普及,现在碎片化学习的倾向已经愈发明显了。而远场语音交互把这个倾向还扩展到了老人和儿童群体,特别是在中国,老人和儿童是文字知识储备最少的两个群体,他们对于远场智能交互的需求更为迫切,这也是智能音箱能在国内快速爆发的重要原因之一。智能音箱甚至让刚学会说话的儿童都开始了碎片化学习,大量的儿童故事和科学故事,让现在的小孩很早就懂得了比我们当初更为丰富的知识。随着他们长大,以及我们当前的知识获取习惯,长期集中系统的学习是否需要变革?或许长期集中在一起的学习更为重要的是要满足人类社交的需求,而不是更好的学习知识。所以,当我们总是批评国人不好好看书的时候,也需要小小反思一下,知识的载体并非只有书籍一种,而书籍的知识更新速度确实太慢了,无法解决我们对于知识爆炸的焦虑。所以,什么样的学习方式才是最好的呢?学习方式本身是不是也应该进化呢?至少,我们知道,当前人类学习知识的方式已经比一百年前迭代进化很多了,下一步是不是机器应该参与到这种人类进化过程呢?
这样来看这个故事很性感,但是同样挑战也是极大。任何一件事情都会有两面性,我们需要从不同角度来审视。人机交互的核心是语言,其最大的挑战其实也是语言。语言是洞悉人类天性的窗口,天然承载了人类的思想和情感,那么怎么才能让机器来承担这种能力呢?这还在探索,至少从现在来看,深度学习好像很难解决这个问题,当前的实践只是证明了深度学习更适合模式识别这个领域,对于语言理解的效果不是那么显著,而脑机接口更是挑战了人类极限,短期内也很难看到实质性成效。

语言更令研究者头疼的是个体的差异性,族群的差异性还好,至少还有一定的规律,但是个体的自由语言却能让其他个体理解,人类甚至还可以“只可意会不可言传”。但是机器不行,机器只能基于数据分析寻找规律,其特殊能力在于能够从海量数据中发现人类难以理解的数据关联,但是人类的能力更强大,只用简单的小样本就可以逻辑推理,这是当前机器学习严重缺失的能力,当前机器学习领域火热的对抗网络、迁移学习等无法解决这个问题。

所以,当前还只是人机自然交互的萌芽状态,即便第4代交互也还任重而道远,幸运的是这项技术已经规模商业化落地,至少突破了可用的及格门槛。若要让这项技术能够持续推进并做好商业化,最为重要的还是基础教育问题,我们从百度指数的分析来看,年轻人对于AI的关注显然还不如30岁以上的人群,所以我们还需要加强这个领域的教育普及,吸引更多的年轻人投身声学语音和语言理解这个行业,也期待更多学术机构能够联合起来,打破学科之间的壁垒,携手培养更多跨学科的年轻人。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4207次2019-11-23 09:39:42
-
浏览量:116次2023-08-30 20:27:59
-
浏览量:969次2023-11-04 10:01:42
-
浏览量:1808次2024-03-08 11:20:33
-
浏览量:1292次2023-05-13 21:35:31
-
浏览量:2350次2018-09-01 14:14:41
-
浏览量:2759次2023-04-23 09:34:59
-
2021-04-12 20:00:58
-
浏览量:150次2023-08-15 18:40:55
-
浏览量:2509次2018-01-28 21:19:25
-
浏览量:2359次2020-04-30 10:47:42
-
浏览量:2347次2018-01-24 22:21:43
-
浏览量:2031次2020-01-03 10:44:52
-
浏览量:1880次2020-06-11 15:30:54
-
浏览量:9659次2020-12-12 14:56:13
-
浏览量:285次2023-08-02 20:35:16
-
浏览量:4299次2019-06-28 10:20:47
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:2492次2020-06-11 14:27:18

tomato
===============













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
tomato

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
